机器学习笔记(二)线性回归 2020-07-07 笔记 暂无评论 1543 次阅读 [TOC] # 线性回归分析 变量之间X、Y之间存在某种密切的联系,但并非严格的函数关系(非确定性关系) ## 回归 回归是处理两个或两个以上变量之间互相依赖的定量关系的一种统计方法和技术,变量之间的关系并非确定的函数关系,通过一定的概率分布来描述。 - 回归是在两个变量之间 - 自变量x - 因变量y - 分类 - 按自变量的多少 - 一元回归 - 多元回归 - 按是不是线性 - 线性回归 - 非线性回归 ## 线性 线性( Linear )的严格定义是一种**映射关系** ,其映射关系满足**可加性**和**齐次性**。 通俗理解就是两个变量之间存在一次方函数关系,在平面坐标系中表现为一条直线。 不满足线性即为非线性( non-linear )。 ## 线性回归 - 线性回归(Linear Regression) 在回归分析中,如果自变量和因变量之间存在着线性关系,则被称作线性回归。 - 一元线性回归 如果只有一个因变量一个自变量,则被称作一元线性回归 - 多元回归 如果有一个因变量多个自变量,则被称作多元回归 ## 模型的一般形式 回归模型的一般形式: y=f(x1,x2,x3,...,xp)+ε - f(x1,x2,...xp) - 是确定性关系 - =β0+β1\*x1+β2\*x2+...+βp\*xp - β0,β1,...βp被称作回归系数 - ε - 是随机误差(扰动项) - 影响因素缺失 - 观测/测量误差 - 其他随机误差 - 预测的时候忽略掉 - y=f(x1,x2,x3,...,xp) - 因为ε没办法估算 - 建模的时候要考虑 - 建模的时候可以用概率分布来研究 ## 几个基本假设 线性回归有几个基本的前置假设条件: - 零均值 - 随机误差项均值为0,保证未考虑的因素对被解释变量没有系统性的影响 - 同方差 - 随机误差项方差相同,在给定x的情况下,ε的条件方差为某个常数σ^2 - 无自相关 - 两个ε之间不想管,cov(εi,εj)=0,i≠j - 正态分布 - ε符合正态分布εi~N(0,σ^2) - 解释变量x1,x2,...,xp是非随机变量,其观测值是常数 - 解释变量之间不存在精确的线性关系 - 样本个数要多于解释变量的个数 ## 建立回归模型的流程 1. 需求分析明确变量 - 了解相关需求,明确场景,清楚需要解释的指标(因变量) - 并根据相关业务知识选取与之有关的变量作为**解释变量**(自变量)。 2. 数据加工处理 - 根据上一步分析得到的解释变量,去搜集相关的数据(时序数据、截面数据) - 时序数据:有时间因素的数据 - 例如房价15年是多少钱、16年是多少钱 - 截面数据:忽略时间因素 - 例如半年内的房价是多少钱 - 对得到的数据进行清洗、加工 - 并根据数据情况调整解释变量 - 并判断是否满足基本假设 3. 确定回归模型 - 了解数据集,使用绘图工具绘制样本散点图 - 或使用其他分析工具分析变量间的关系 - 根据结果选择回归模型 - 如:线性回归模型、指数形式的回归模型等 4. 模型参数估计 - 模型确定后,基于搜集、整理的样本数据,估计模型中的相关参数。 - 最常用的方法是最小二乘法 - 在不满足基本假设的情况下还会采取岭回归、主成分回归、偏最小二乘法等。 5. 模型检验优化 - 参数确定后,得到模型,此时需要对模型进行统计意义上的检验。 - 对回归方程的显著性检验 - 方程本身是不是显著的 - 即方程有没有意义 - 方程要全是随机因素,就没意义 - 回归系数的显著性检验 - 例如y=β0+β1\*x1+β2\*x2 - 如果自变量x1对结果没有实际的影响,那么参数β1就没意义。 - 如果自变量x1对结果的影响是随机原因造成的,不显著,那么参数β1也没意义,要把β1\*x1这一项去掉。 - 拟合优度检验 - 看拟合效果好不好。 - 即能不能兼顾大多数的点。 - 即损失函数最小。 - 异方差检验 - 数据本身有没有问题 - 即随机误差有没有规律 - 万一随机误差有规律,就要把这个规律找出来,放到前面的方程里去。 - 零均值,同方差,正态分布,无自相关 - 多重共线性检验 - 例如y=β0+β1\*x1+β2\*x2 - 如果x1与x2有函数关系,或者相似度非常高,那么x2就没有存在意义了,直接把x2用x1表示出来,加到方程里去。 - 多重共线性对模型影响非常大。 - 结合实际场景,判断该模型是否有实际意义 - 判断模型对工作是不是有帮助 6. 模型部署应用 - 模型检验通过后,可以使用模型进行相关的分析、应用,包括因素分析、控制、预测等。 ### 例子:预测波士顿房价 1. 房价与一下因素有关: - 面积,位置,房龄,户型,周围环境…… 2. 搜集有效数据: - 面积:无相关信息 - 位置:离商业中心的距离DIS - 房龄:AGE - 户型:房间数RM - 周围环境:环保指标NOX、是否沿河CHAS - 便利程度:距离高速的距离RAD - 邻居:教师学生比例PTRATIO、城市中黑人比例B、低收入阶层LSTAT - 学校:无相关信息 - 新增:人均犯罪率CRIM、住宅用地比例ZN、商业用地比例INDUS、税率TAX 3. 指数型回归模型 - C-D(柯布-道格拉斯)生产函数: - y=AK^αL^βμ - y是工业总产值 - A是综合技术水平 - L是劳动力数(万人) - K是投入资本(亿元) - α是劳动力产出弹性系数 - β是资产产出弹性系数 - μ是随机干扰 - 说明两点: 1. 可以选择现有的、比较成熟的模型公式 2. 指数可以转成对数,来简化计算:y=ln(A) + αln(K) + βln(L) + ln(μ) 4. 最小二乘法 - (Least Square Method)也叫最小平方法。 - 通过最小化误差的**平方和**寻找数据的最佳函数匹配的方法。 - 为什么对误差取**平方和** 1. 都是非负的,不会因为正负相加而抵消 2. 平方计算起来比较方便 3. 平方(二次)求导变成一次,计算比较简单 5. 显著性检验 - [假设检验在模型比较中的应用,t检验,F检验](https://www.proup.club/index.php/archives/275/#以一元线性回归为例) 6. 使用模型进行分析、应用 - 变量关系 - 确定几个特定变量之间是否存在相关关系,如果存在的话,找出它们之间合适的数学表达式 - 因素分析 - 回归模型对解释变量和被解释变量之间关系进行了度量,从各个解释变量的系数可以发现各因素对最终结果的影响大小 - 控制 - 给定被解释变量的值,根据模型来控制解释变量的值 - 预测 - 根据回归模型,可以基于已知的一个或多个变量预测另一个变量的取值,并可以了解这个取值精确到什么程度 ## 回归模型的特点 回归模型很老,但应用的很多。 很多人吐槽回归模型不好用,实际上是因为没用对,必须满足[几个基本假设](#几个基本假设) ### 回归模型的优点 - 模型简单,建模和应用都比较容易 - 有坚实的统计理论支撑 - 定量分析各变量之间的关系 - 模型预测结果可以通过误差分析精确了解 ### 回归模型的缺点 - 假设条件比较多且相对严格 - 变量选择对模型影响较大 # 一元线性回归模型 **一元线性理论回归模型为:** $$y=\beta_0+\beta_1x+\epsilon $$ - y:被解释变量(因变量) - β0:回归常数 - β1:回归系数 - x:解释变量(自变量) - ε:随机误差 - E(ε)=0,ε的均值为0 - var(ε)=σ^2,ε的方差是常数(必须是在可接收的浮动范围内的常数) **一元线性回归方程** $$E(y)=E(\beta_0+\beta_1x+\epsilon)$$ $$y=\beta_0+\beta_1x$$ 回归方程从平均意义上表达了变量y与x的统计规律性。 回归分析的主要任务,就是通过n组样本的观察值,对β0、β1进行估计,得到最终方程。 ## 参数估计 ### 最小二乘估计 - 最小二乘估计(Ordinary Least Square Estimation,OLE) - 根据观察数据,寻找参数β0、β1的估计值^β0、^β1,使观察值和回归预测值的**离差平方和**达到极小。 - 离差平方和: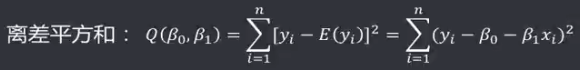 - 估计值: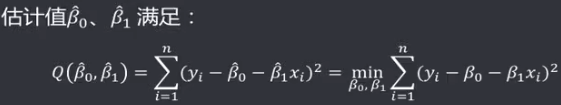 - 估计值^β0、^β1称作回归参数β0、β1的最小二乘估计。读作“beta0 hat”,"beta1 hat"。 - Q(^β0,^β1)是非负二次函数,有最小值。 #### 最小值的求法 - 其**最小值的求法**为:求其**偏导数**,令其偏导数**分别等于零**,**求解方程组**即可。  这是有两个方程(∂Q/∂β0,∂Q/∂β1)、两个变量(^β0和^β1)的方程组,是可以解出来的。 解出来的结果是: 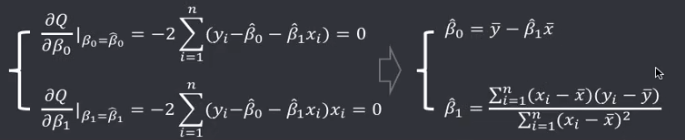 ### 最大似然估计 - 最大似然估计(Maximum Likelihood Estimation,MLE) - 利用总体的分布密度或概率分布的表达式及其样本所提供的信息求未知参数估计量的一种方法。 - 基本思路:已知样本符合某种分布,但分布的具体参数未知,通过实验,估算分布的参数。 - 估算的思想为:已知某组参数能使当前样本出现的概率最大,就认为该参数为最终的估计值。 - 解决的是“**模型已定,参数未知**”的问题。即用已知样本的结果,取反推既定模型中的参数最可能的取值。 >例如:投掷一枚质地不均匀的硬币,正反面的结果符合二项式分布: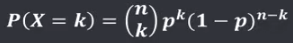 其中n和k为与实验相关的常数,p为出现正面的概率,也是待确定的参数。 将硬币投掷i次,出现正面的次数为j,在没有其他更多信息的情况下,则有理由相信p=j/i。 #### 最大似然估计的求法 1. 出现当前情景的概率为:f(x1,x2,...xn|θ)=f(x1|θ)f(x2|θ)...f(xn|θ),θ未知 2. 称其为似然函数L:L(θ|x1,x2,...xn)=f(x1,x2,...xn|θ)=f(x1|θ)f(x2|θ)...f(xn|θ)=∏(i=1:n,f(xi|θ)) 3. 为了方便计算,取对数:lnL(θ|x1,x2,...xn)=lnf(x1|θ)+lnf(x2|θ)+...+lnf(xn|θ)=∑(i=1:n,lnf(xi|θ)) 4. 平均对数似然 ^l 记做:^l=(1/n)lnL(θ|x1,x2,...xn) 5. 最大似然估计就是找到一个θ使 ^l 最大,即: 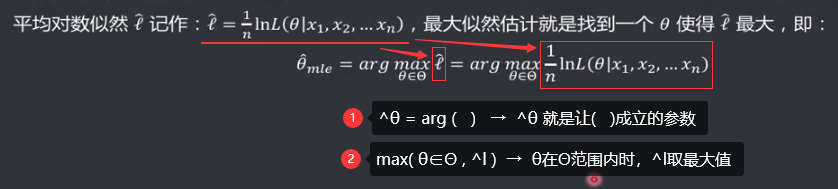 #### 最大似然估计的数学推导 总体X为连续性分布,其分布密度族为{f(x,θ),θ∈Θ},假设总体X的一个独立同分布的样本为x1,x2,...xn,其似然函数为:L(θ|x1,x2,...xn)=∏(i=1:n,f(xi|θ))。 最大似然估计应在一切θ中选取随机样本(X1,X2,...Xn)落点在(x1,x2,...xn)附件概率最大的^θ作为θ的估计值, 即^θ满足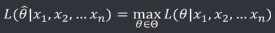 ### 有偏估计与无偏估计 - 无偏估计(Unbiased Estimate) - 用样本统计量来估计总体参数时的一种无偏推断 - 估计量的数学期望等于估计量的真实值 - 即E(^θ)=θ - 换言之,在对某量进行估计时,针对不同的样本,估计结果对真实值来说有的偏大有的偏小,反复多次,“平均”来说,和真实值的偏差为0。 - 反之,则为**有偏估计(Biased Estimate)** - 无偏估计无系统性偏差 - 有偏估计有系统性偏差。 ## 显著性检验 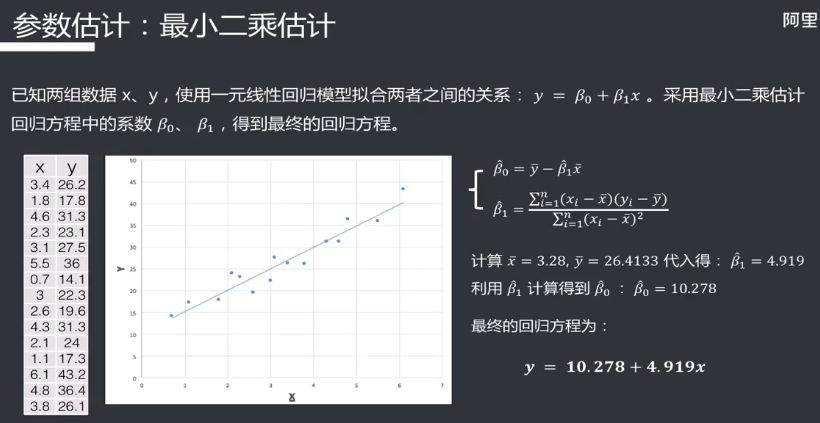 y=10.278+4.919x ### 回归系数是否显著:t检验 因变量y与自变量x之间是否存在线性关系,即β1是否等于0,使用t检验进行判断。 > 拟合的效果好,不一定是真的存在线性关系,可能是误差造成的。 1. 确定假设 我们收集证据是为了找到不达标的证据,即原假设H0:β1=0,备择假设H1:β1≠0 2. 确定检验水平 采取常用的α=0.05,或是更严格的α=0.01 3. 构造统计量 - H0成立时:^β1~N(0,(σ^2)/Lxx) - 正态分布 - 均值是β1,假设β1是0 - 构造t统计量: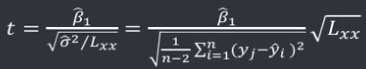 4. 比较p值和α值 - 计算t统计量,符合自由度n-2的t分布,双尾检测,查临界值表,找到p值 5. 得到结论 - p值若大于α值,不能拒绝原假设。 - 即通过本次采样得到的样本数据,并不能证明原假设H0不成立, - 即本次得到的回归系数β1无显著统计意义,需重新建模。 方法1:查表查t值 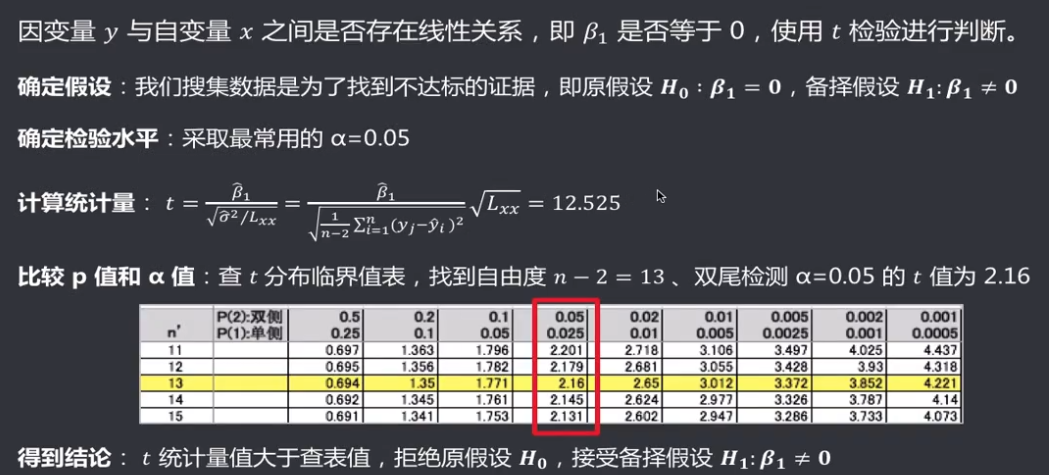 方法2:不查表,而是计算p值  ### 回归方程是否显著:F检验 平方和的分解式: 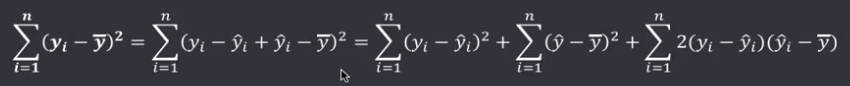  - SST(总离差平方和) -  - 因变量y的波动程度(不确定性) - SSE(残差平方和) - 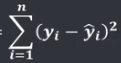 - 由其他未控制因素引起的波动 - SSR (回归平方和) - 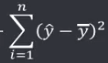 - 由自变量x引起的波动 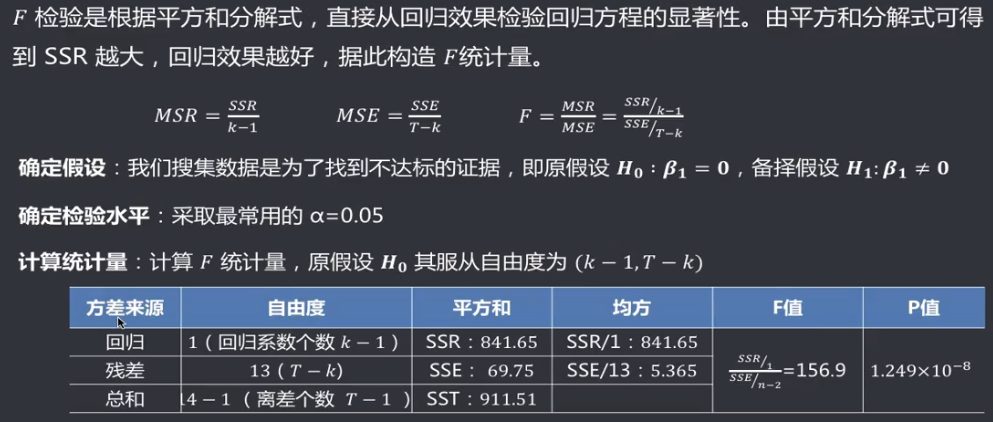 F检验是根据平方和分解式,直接从回归效果 检验回归方程的显著性。 由平方和分解式可得到SSR越大,回归效果越好,由此构成F统计量。 MSR = SSR / (k-1) MSE = SSE / (T-k) F = MSR / MSE = (SSR / (k-1)) / (SSE / (T-k)) - k:回归系数个数 - T:离差个数 ### 相关系数显著性检验:t检验 - 相关系数(Correlation Coefficient) - 描述了变量之间的线性相关程度的量 - 一般用字母r表示 - 有多种定义方式,一般是指皮尔逊相关系数 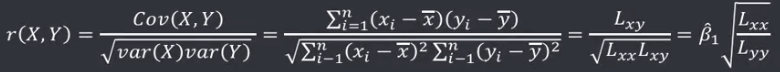 - Cov(X,Y):XY的协方差 - var(X):X的方差 - Lxx,Lxy,Lyy的定义 - ^β1:β1的估计值 - r的取值范围为[-1,1] - r>0表示正相关 - r<0表示负相关 - r=0表示不相关 **样本相关系数r** 可作为**总体相关系数ρ**的估计值。(因为总体的数据是取不到的,只能用已经拿到的样本) 但从相关系数ρ=0的总体中抽出来的样本,计算其相关系数r,因为有抽样误差,所以不一定是0。 要判断不等于0的r值是来自ρ=0的总体还是来自ρ≠0的总体,必须进行显著性检验。 1. 确定假设 我们搜集数据是为了找到不达标的证据,即原假设H0:ρ=0,备择假设H1:ρ≠0 2. 确定检验水平 采取比较严格的α=0.01 3. 计算统计量 - 计算t统计量,原假设H0成立,t=sqrt(n-2r) / sqrt(1-r^2) 4. 计算p值 - n=15 - r=0.9610 - t=13.07 - 计算得到p=7.432*10^-9 - 也可以查相关系数临界值表,查到α=0.01,degree=13对应的值为0.641,小于计算得到的t值。 5. 得到结论 p<α,拒绝原假设H0,接受备择假设H1:ρ≠0 ## 决定系数 通过平方和分解式SST=SSR+SSE,SSR占的比重越大,线性回归效果越好,即回归直线与样本观测值的拟合优度越好。 定义回归平方和占总离差平方和的比例为**决定系数**(Coefficient of Determination),也称**确定系数**,记做r^2 $$r^2=\frac{SSR}{SST}=\frac{\sum^n_{i=1}(\hat{y}_i-\bar{y})^2}{\sum^n_{i=1}(y_i-\bar{y})^2}$$ 决定系数是一个相对的指标,取值在0~1之间,接近1表明回归方程拟合效果较好。 但要注意几点: - 样本量较小时,决定系数并不能真正反映实际情况,需要调整决定系数 - 决定系数较大,同样也不能肯定自变量与因变量之间的关系就是线性的,可能曲线拟合更好,特别当自变量取值范围较小时,决定系数通常较大,可以做模型失拟检验(Lack of Fit Test) - 决定系数较小,如果样本量较小,则得到线性回归不显著的结果,如果样本量较大,则会得到线性回归显著;最后改进回归,如增加自变量、尝试曲线回归拟合等。 ## Anscombe's Quartet 1973年统计学家F.J.Anscombe构造了四组数据,x,y的均值、方差都一样,并且其经验回归方差相同:y=3+0.5x,决定系数r^2=0.667,F统计量相同 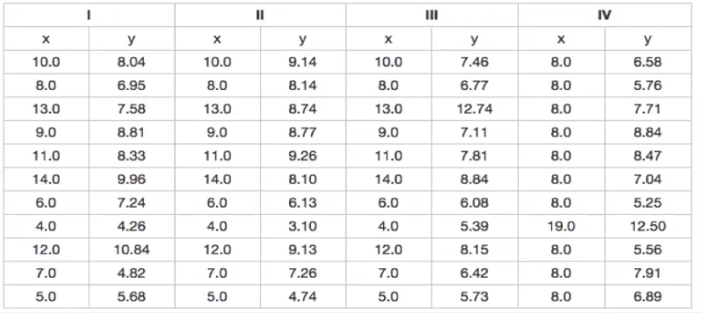 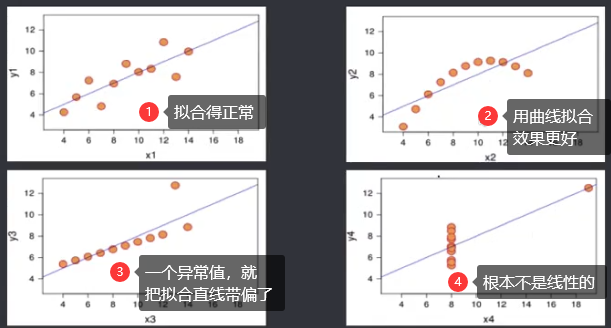 即使能算的量(均值、方差、方程、决定系数、F统计量)都一样,未必证明线性回归真的好用。 标签: none 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭