pytorch-mnist笔记 2020-08-01 笔记,实验 暂无评论 2019 次阅读 [TOC] # 一句话介绍mnist 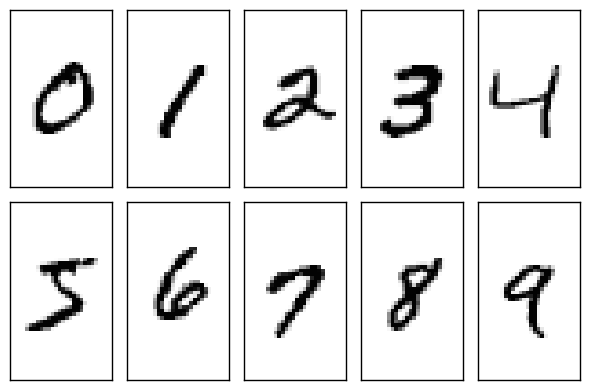 mnist是“手写数字”的数据集,能用来训练分类模型。 # 一、运行例程 ## 1.1 例程代码: 代码来源:https://github.com/pytorch/examples/blob/master/mnist/main.py ```python from __future__ import print_function import argparse import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from torch.optim.lr_scheduler import StepLR class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: break def test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)') parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing (default: 1000)') parser.add_argument('--epochs', type=int, default=14, metavar='N', help='number of epochs to train (default: 14)') parser.add_argument('--lr', type=float, default=1.0, metavar='LR', help='learning rate (default: 1.0)') parser.add_argument('--gamma', type=float, default=0.7, metavar='M', help='Learning rate step gamma (default: 0.7)') parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training') parser.add_argument('--dry-run', action='store_true', default=False, help='quickly check a single pass') parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='how many batches to wait before logging training status') parser.add_argument('--save-model', action='store_true', default=True, help='For Saving the current Model') args = parser.parse_args() use_cuda = not args.no_cuda and torch.cuda.is_available() torch.manual_seed(args.seed) device = torch.device("cuda" if use_cuda else "cpu") kwargs = {'batch_size': args.batch_size} if use_cuda: kwargs.update({'num_workers': 1, 'pin_memory': True, 'shuffle': True}, ) transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) dataset1 = datasets.MNIST('../data', train=True, download=True, transform=transform) dataset2 = datasets.MNIST('../data', train=False, transform=transform) train_loader = torch.utils.data.DataLoader(dataset1,**kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **kwargs) model = Net().to(device) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) for epoch in range(1, args.epochs + 1): train(args, model, device, train_loader, optimizer, epoch) test(model, device, test_loader) scheduler.step() if args.save_model: torch.save(model.state_dict(), "mnist_cnn.pt") if __name__ == '__main__': main() ``` ## 1.2 例程输出 第一个Train Epoch: ``` Train Epoch: 1 [0/60000 (0%)] Loss: 2.333409 Train Epoch: 1 [640/60000 (1%)] Loss: 1.268057 Train Epoch: 1 [1280/60000 (2%)] Loss: 0.859085 . . . Train Epoch: 1 [58240/60000 (97%)] Loss: 0.021440 Train Epoch: 1 [58880/60000 (98%)] Loss: 0.032908 Train Epoch: 1 [59520/60000 (99%)] Loss: 0.122419 Test set: Average loss: 0.0563, Accuracy: 9807/10000 (98%) ``` 第二个Train Epoch: ``` Train Epoch: 2 [0/60000 (0%)] Loss: 0.044964 Train Epoch: 2 [640/60000 (1%)] Loss: 0.100205 Train Epoch: 2 [1280/60000 (2%)] Loss: 0.062408 . . . Train Epoch: 2 [58240/60000 (97%)] Loss: 0.113988 Train Epoch: 2 [58880/60000 (98%)] Loss: 0.035375 Train Epoch: 2 [59520/60000 (99%)] Loss: 0.020242 Test set: Average loss: 0.0346, Accuracy: 9886/10000 (99%) ``` 最后一个Train Epoch: ``` Train Epoch: 14 [0/60000 (0%)] Loss: 0.236364 Train Epoch: 14 [640/60000 (1%)] Loss: 0.004772 Train Epoch: 14 [1280/60000 (2%)] Loss: 0.002449 . . . Train Epoch: 14 [58240/60000 (97%)] Loss: 0.002534 Train Epoch: 14 [58880/60000 (98%)] Loss: 0.031061 Train Epoch: 14 [59520/60000 (99%)] Loss: 0.005676 Test set: Average loss: 0.0251, Accuracy: 9919/10000 (99%) ``` # 二、看输出 参考:https://www.jianshu.com/p/e5076a56946c ## 2.1 Train Epoch ### Epoch >epoch 英 [ˈiːpɒk] 美 [ˈepək] n.时代; 纪元; 时期; 世(地质年代,纪下分世) Epoch是一个训练周期,在这个训练周期中,会用尽训练集的全部数据。 MNIST训练集,有60000条数据。 例程设置的Epoch是14轮,也就是把60000条数据来回用14次。 Epoch设置得少,会导致欠拟合。 (例如Epoch设置成1轮,相当于从随机位置出发,往最优方向只走一步) Epoch设置得多,会导致过拟合。 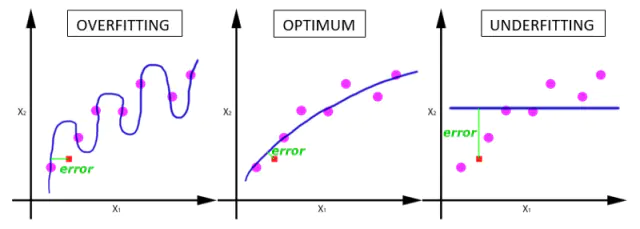 ### Batch >batch 英 [bætʃ] 美 [bætʃ] n.一批;(食物、药物等)一批生产的量;批 v.分批处理 训练集中的数据分批送到网络中训练,一批数据就是一个Batch。 例程设置的Batch-Size是64。 >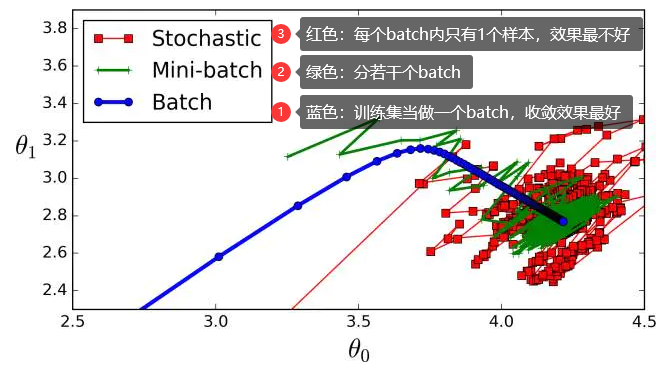 ### Iterations 完成一次epoch所需的batch个数。 ## 2.2 Loss 损失函数,反映模型输出值与实际标记值之间的误差。 例程用的损失函数是`nll_loss`,(The negative log likelihood loss),负对数似然损失。 参考:[NLLLOSS](https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html#torch.nn.NLLLoss) 参考:[What are C classes for a NLLLoss loss function in Pytorch?](https://stackoverflow.com/questions/59718130/what-are-c-classes-for-a-nllloss-loss-function-in-pytorch) nll_loss适合处理“类别明确”的分类问题。好比NMIST数据集,能确定是分10个类别(10个数字,一个数字对应一类)。 模型输出值,是训练数据对应各个类别的概率。 实际标记值,是训练数据对应的类别序号。 损失函数的输出,有三种表示方式: - 列向量,`reduction="none"`:列向量的每一个元素,分别对应Batch中的一个样本。 - 取平均值,`reduction="mean"`:一个Batch中所有样本的损失值取平均值。 - 总和,`reduction="sum"`:一个Batch中所有样本的损失值求和。 L1损失:$$l_n=|x_n-y_n|$$ > 有一个和这有点像的概念:[L1范数](https://www.proup.club/index.php/archives/275/#%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%96%B9%E6%B3%95%E7%9A%84%E4%B8%89%E8%A6%81%E7%B4%A0) >L1就是绝对值的意思。 >L2就是平方。 MSE(均方损失):$$l_n=(x_n-y_n)^2$$ - l代表loss,损失。 - n代表Batch中的第n个**样本**(不是第n个类别) - xn代表模型作用于第n个样本的输出值。 - yn代表第n个样本的标记值。 ### 负对数似然损失 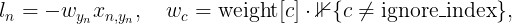 负对数似然损失适合“类别明确”的分类,这是因为: - 模型的输出值是一个一维向量。 - 例如MNIST肯定有10类,那么模型输出的就是长度为10的矩阵。 - 输入一张手写数字图片,输出这张图片是数字0、数字1、...数字9的概率,这个结果是长度为10的矩阵。 - 样本的标记值是一个下标。 - 例如数字3的手写图片,下标就是3。 - 有向量x[10],有下标y=3,取x[y]很容易 - 但x不能直接用模型输出的概率矩阵 - 而是稍微变换一下 1. 归一化(让矩阵所有元素之和为1) 2. 取对数(原元素越大,越接近0,但全是负数) 3. 取负数(原元素越大,越接近0,且全是正数) 4. [可选] 乘一个权重。(某一类型的样本越多,权重就越大,损失值越准确) 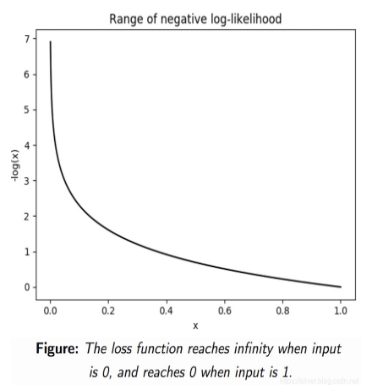 例子: - 一个Batch里有三个样本:数字1,数字0,数字4 的手写图片。 - 此Batch的标记就是 y=[1,0,4] - `y0=1, y1=0, y2=4` - 这个Batch用模型算出来概率矩阵是3行10列的矩阵。好比: ``` ans=[[0.52,0.22,0.01,0.04,0.18,……], [0.44,0.34,0.05,0.05,0.10,……], [0.17,0.08,0.30,0.07,0.36,……]] ``` - 对结果进行变换:归一化、取对数、取负数。结果: ``` x=[[1.30,1.60,1.81,1.78,1.63,……], [1.37,1.47,1.77,1.76,1.71,……], [1.64,1.73,1.51,1.74,1.44,……]] ``` - 如果对结果x再进行同样的变化,结果不变。 - 得到本次训练的损失值。损失值的三种表示方式——列向量,平均值,总和。 - 例如列向量,就是: ``` [[1.60], (也就是x[0][y0]=x[0][1]) [1.37], (也就是x[1][y1]=x[1][0]) [1.44]] (也就是x[2][y2]=x[2][4]) ``` - 例如平均值,就是:`(1.60 + 1.37 + 1.44)/3 = 1.47` - 例如求和,就是:`1.60 + 1.37 + 1.44 = 4.41` # 三、看过程 例程的主循环有三行代码: ``` train(),训练 test(),测试 scheduler.step(),好像是调度器进行下一步 ``` Train Epoch设置多少,主循环就循环几次。 ## 3.1 train比test多了什么 ### 3.1.1 准备工作 **内核部分** train的第一行代码是:`model.train()` test的第一行代码是:`model.eval()` 参考:[nn.Module](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module) model是用户定义的Net类,Net类是基于`nn.Module`基类,字面翻译成“神经网络模块”。`.train()`和`.eval()`都是神经网络模块的方法。 - eval()把神经网络模块设置成“评估模式”,这样往模型送入数据,就不会改变模型了。 - train()把神经网络模块设置成“训练模式”。 **模型部分** test用往模型送数据计算损失的全过程,都用`with torch.no_grad():`括起来。 train没有这个。 参考:[torch.no_grad()](https://blog.csdn.net/weixin_46559271/article/details/105658654) - torch.no_grad() 是一个上下文管理器,被该语句 wrap 起来的部分将不会track 梯度。 ### 3.1.2 遍历数据 **相同点** train和test传数据用的train_loader、test_loader都是`torch.utils.data.DataLoader`,区别只是载入的数据集不一样,一个训练集一个测试集。 参考:[torch.utils.data.DataLoader](https://pytorch.org/docs/stable/data.html) DataLoader是可以遍历的,相当于由`(样本数据,标记)`元组组成的数组。 在初始化DataLoader的时候,加上batch_size参数,用来决定每次遍历几个数据。 如果用CUDA,会加三个参数: ``` {'num_workers': 1, 设置多少个读取数据的子进程。0表示在主进程读取数据。 'pin_memory': True, 把tensor放到CUDA固定的内存。 'shuffle': True} 每读完一轮全部数据,对数据“洗牌”。 ``` **不同点** train的遍历方式是: `for batch_idx, (data, target) in enumerate(train_loader):` test的遍历方式是: `for data, target in test_loader:` - enumerate()是Python的语法。 - 普通的`for x in arr:`,是直接遍历**元素**; - 而`for i,x in enumerate(arr):`,遍历的是**(下标,元素)**。 ### 3.1.3 使用模型 - train 1. 用优化器 2. 损失值是取平均值 3. 不看预测正确的样本数量 - test 1. 不用优化器 2. 损失值是取总和 3. 看预测正确的样本数量 #### 优化器 字面意思,optimizer是优化器,在主循环之前定义: ``` device = torch.device("cuda" if use_cuda else "cpu") model = Net().to(device) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) ``` 参考:[torch.optim](https://pytorch.org/docs/stable/optim.html) 参考:[nn.Module.parameters()](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.parameters) - 优化器可以根据算出来的梯度,来更新模型参数。 - 如果用CUDA,需要在**构造优化器之前**,把模型对象挪到CUDA上。 - 如果先构造优化器,后把模型挪到CUDA,那么优化器里的参数就和模型在CUDA上的参数不是同一份了。 - 创建模型实例,就立即挪到cpu或cuda上。`model = Net().to(device)` - 优化器在构造的时候,要传入模型参数,模型参数必须能遍历。 - `model.parameters()` 能返回模型所有参数,能用来构造优化器。 - 参数的数组`[var1 , var2]`也能构造优化器。 - 优化器在构造的时候,要设置学习率lr(learning rate) - 例程设置的默认lr是1.0 - 可以给神经网络模型的每一层的参数设置不同的优化器。 **例程用的是基于Adadelta算法的优化器。** - Ada = Adaptive 自适应 - delta = 增量 - 参考:[ADADELTA: An Adaptive Learning Rate Method](https://arxiv.org/abs/1212.5701) **优化器的用法:** 优化器的step()方法,会更新模型的参数。 优化器的两种用法,例程用的是第一种。 1. 大部分优化算法都能用的简化版本,计算完梯度就优化参数。 ``` for input, target in dataset: optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() optimizer.step() ``` 2. 个别优化算法,例如共轭梯度、LBFGS,需要多次重新评估函数。因此需要传入一个“复位梯度、计算损失”的闭包。 ``` for input, target in dataset: def closure(): optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() return loss optimizer.step(closure) ``` #### 看预测正确的样本数量 ##### 模型的输入与输出 样本数据,即模型的输入,是尺寸为[64, 1, 28, 28]的tensor。 样本标记,是尺寸为[64]的tensor。 模型的输出,是尺寸为[64, 10]的tensor。 ##### 由模型输出得到预测结果 参考:[torch.argmax()](https://pytorch.org/docs/stable/generated/torch.argmax.html#torch.argmax) - argmax() - 返回的是tensor最大值的下标 - 是max()的第二个返回值。 - dim = dimension 维度 - keepdim : 保持维度不变(原本是列矩阵的,维持列矩阵) - 例如:output是尺寸为[64,10]的tensor - output.argmax() 返回一个数字。 - output.argmax(dim=1) 返回[64]的数组。 - output.argmax(dim=1,keepdim=True) 返回[64,1]的列向量。 - output.argmax(dim=0) 返回[10]的数组。 - output.argmax(dim=0,keepdim=True) 返回[1,10]的列向量。 - output.argmax(dim=2) 报错 - Dimension out of range (expected to be in range of [-2, 1], but got 2) - output.argmax(dim=-1) 返回[64]的数组。 - output.argmax(dim=-1,keepdim=True) 返回[64,1]的列向量。 - output.argmax(dim=-2) 返回[10]的数组。 - output.argmax(dim=-2,keepdim=True) 返回[1,10]的列向量。 - A.view_as(B) - A和B是两个尺寸不一样的tensor。 - 返回一个尺寸和B一样的A。 - A.eq(B) - A和B是两个尺寸一样的tensor。 - 返回一个由True和False组成的tensor,尺寸与A和B一样。 - A.sum() - A是一个tensor。 - 返回tensor所有元素之和,是一个数字。 - A.item() - A是一个数字(尺寸为[])的tensor - 返回A的值(由tensor类型转为数字类型) ## 3.2 scheduler是干什么的 参考:[torch.optim.lr_scheduler](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) lr_scheduler是调整学习率的。 >- optimizer是在batch与batch之间,根据梯度,来更新模型的参数; >- lr_scheduler是在epoch与epoch之间,根据epoch数,来缩小optimizer的学习率。 - lr_scheduler在构造的时候,要传入优化器。 参考:[StepLR](https://pytorch.org/docs/stable/optim.html#torch.optim.lr_scheduler.StepLR) 例程用的 StepLR 会周期性地减少学习率。 - step_size:每多少epoch减少一次。 - gamma:每次是令学习率乘以多少。 ``` >>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 60 >>> # lr = 0.0005 if 60 <= epoch < 90 >>> # ... >>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step() ``` # 四、看模型 ## 训练成果 模型的训练成果,即模型状态,也就是由`(参数名,参数)`组成的OrderedDict(有序字典)。 ### 模型状态的存取 **保存** 在训练完成以后,主函数结束之前,加上: ``` torch.save(model.state_dict(), "mnist_cnn.pt") ``` **读取** 在创建模型实例后,优化器之前,加上: ``` model.load_state_dict(torch.load("mnist_cnn.pt")) ``` ### 模型状态与模型参数的区别 1. 获取方式 - 模型状态:`model.state_dict()` - 模型参数:`model.parameters()` 2. 显示方式 - 模型状态:直接print即可 - 模型参数:需要用for来逐个print 3. 元素: - 模型状态:(名称,tensor) - 模型参数:tensor ### 模型的参数 模型的参数,是根据神经网络的“层”,自动生成的,不是手动定义的。 例程中的模型,有以下“层”: ``` def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) 两个“卷积”层 self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout2d(0.25) 两个“丢弃”层 self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(9216, 128) 两个“线性”层 self.fc2 = nn.Linear(128, 10) ``` 模型的参数有8个tensor,这些参数分别是: | 参数名| tensor尺寸 | | :------------: | ---------------------- | |'conv1.weight' | torch.Size([32, 1, 3, 3]) | |'conv1.bias' | torch.Size([32]) | |'conv2.weight' | torch.Size([64, 32, 3, 3]) | |'conv2.bias' | torch.Size([64]) | |'fc1.weight' | torch.Size([128, 9216]) | |'fc1.bias' | torch.Size([128]) | |'fc2.weight' | torch.Size([10, 128]) | |'fc2.bias' | torch.Size([10]) | “丢弃”层 没有参数。 其余每层有两个参数,一个weight权重(卷积核),一个bias偏差。 ## 为什么有的层有参数,有的层没参数 ### Conv2d 参考:[torch.nn.Conv2d](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d) [模型的输入与输出](#模型的输入与输出): >样本数据,即模型的输入,是尺寸为[64, 1, 28, 28]的tensor。 样本标记,是尺寸为[64]的tensor。 模型的输出,是尺寸为[64, 10]的tensor。 - Conv2d的输入的尺寸:(N,C_in,H,W) - Conv2d的输出的尺寸:(N,C_out,H_out,W_out) - N : batch-size - C : Channel 通道 - H : Height 高度 - W : Width 宽度 - Conv2d的参数: - in_channels:输入的通道数 - out_channels:输出的通道数 - kernel_size:卷积核大小 - stride :卷积的步幅 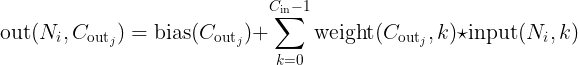 看公式,Conv2d有两个参数:卷积核,偏差。 卷积核Weight用来和输入的图片做“互相关”运算(cross-correlation),然后加上偏差bias。 **卷积核和偏差都是需要训练的,所以卷积层有两个参数。** 参考:[Cross-correlation](https://en.wikipedia.org/wiki/Cross-correlation) 参考:[卷积和互相关的一点探讨](https://zhuanlan.zhihu.com/p/33194385) 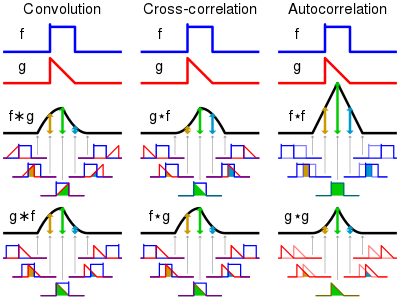 - Convolution是卷积,符号:* - A\*B,与B\*A,一样。 - A\*B就相当于A⋆翻转的B - Cross-correlation是互相关,符号:⋆ - A⋆B,与B⋆A,不一样。 - Autocorrelation是自相关 **例如:灰色大的是图像,黄色小的是卷积核** 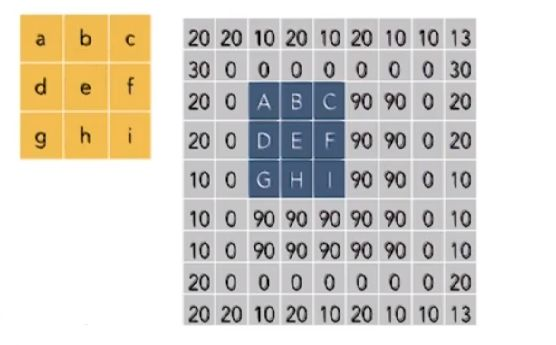 - 对图像蓝色区域进行**互相关**运算,就是: 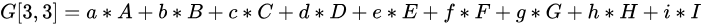 - 对蓝色区域做**卷积**运算,就是: 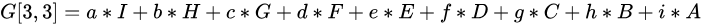 - 相当于把卷积核上下翻转、左右翻转以后再做互相关运算。 **互相关的公式更好看,为什么卷积要翻转卷积核:** 下图是互相关运算的例子。 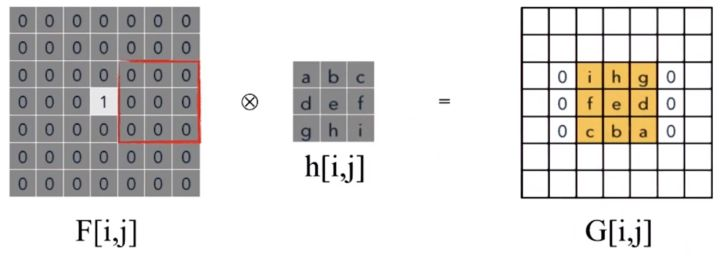 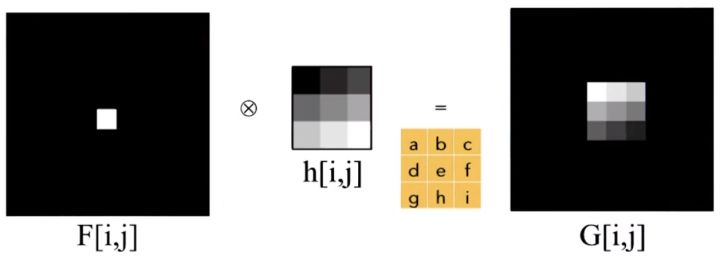 原图像是黑色中央的一个白点; 卷积核是3x3的小图像。 按照互相关的公式,计算结果里,卷积核的图像是上下左右颠倒的。 如果是自己画卷积核,遇到这样的原图,肯定是希望卷积核能原样bia到原图上,而不希望贴个上下左右颠倒的。 但是在神经网络模型里,卷积核不是给人看的图片,所以不讲究上下左右方向,用“公式好看”的互相关,不用卷积。 ### Linear Linear是对输入数据做线性变换的。 参考:[torch.nn.Linear](https://pytorch.org/docs/stable/generated/torch.nn.Linear.html) - 公式是:$$y=xA^T+b$$ - x:输入 - y:输出 - A:变换矩阵 - b:偏差 **矩阵A和偏差b是需要训练的。所以线性层也有两个参数。** ### dropout2d 参考:[torch.nn.Dropout2d](https://pytorch.org/docs/stable/generated/torch.nn.Dropout2d.html) 经过丢弃层的数据,尺寸不变,随机把一些元素置0。 **每次都是独立随机的,不需要训练参数。** ## 从模型输入到模型输出 ``` def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output ``` 1. def forward(self, x): - 此时的x是一个batch的样本数据 - 尺寸为[64,1,28,28] - 64个样本,1个通道,28x28的图片 2. self.conv1(x) - 与nn.Conv2d(1,32,3,1)卷积。 - 输入通道数:1 - 输出通道数:32 - 卷积核大小:3 (3x3的卷积核) - 卷积步幅:1 - x的尺寸变成了[64,32,26,26] - 样本数始终是64 - 通道变成了32个 - 由于是卷积,边角会收缩一点 3. F.relu(x) - 用relu激活函数,把负值全部变成0。 - x的尺寸不变,还是[64,32,26,26] 4. self.conv2(x) - 与nn.Conv2d(32,64,3,1)卷积 - 输入通道32个 - 输出通道64个 - 卷积核尺寸3x3 - x的尺寸变成[64,64,24,24] - 通道数变成64 - 卷积,图片边角再次收缩一点 5. F.relu(x) - 用relu激活函数,把负值全部变成0。 - x的尺寸不变,还是[64,64,24,24] 6. F.max_pool2d(x, 2) - 池化 - 池化核大小:2(2x2合一) - 参考:[torch.nn.MaxPool2d](https://www.jianshu.com/p/9d93a3391159) 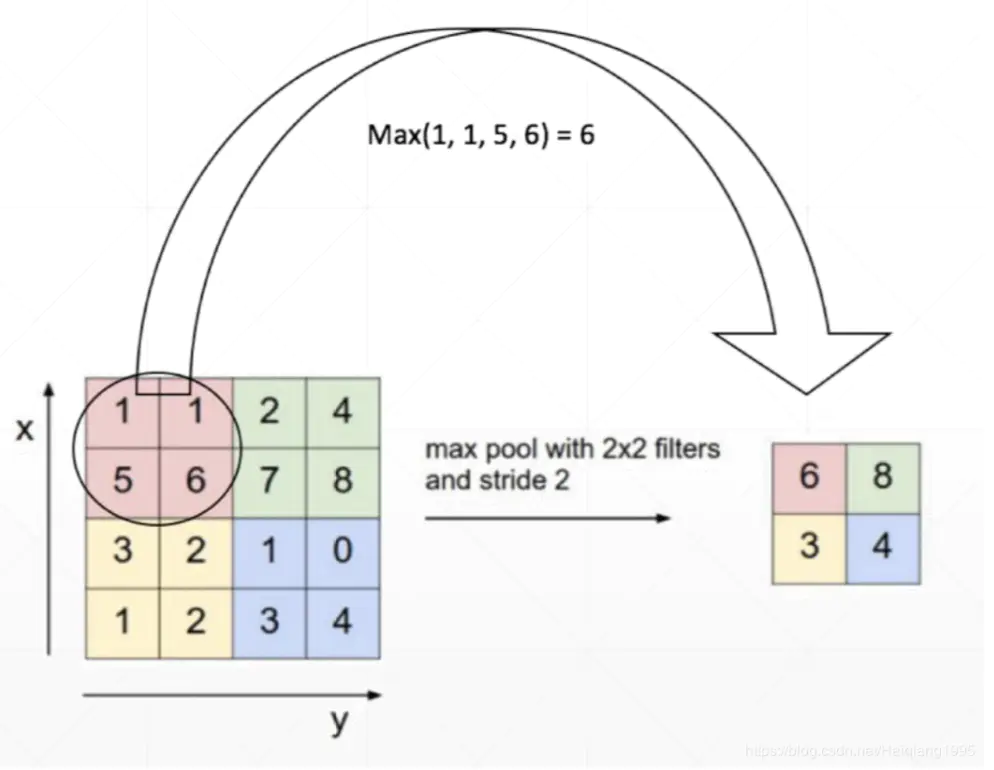 - x的尺寸变成[64,64,12,12] - 图像长宽变为原来的一半。 7. self.dropout1(x) - 随机把25%的元素置0 - droupout1 = nn.Dropout2d(0.25) - x的尺寸不变,还是[64,64,12,12] 8. torch.flatten(x, 1) - 把每个样本的“通道”、“长”、“宽”三维变平成一维。 - x的尺寸变为[64,9216] - 64×12×12=9216 9. self.fc1(x) - 线性变换 - fc1 = nn.Linear(9216, 128) - 由[9216]变成[128] - x的尺寸变为[64,128] 10. F.relu(x) - 用relu激活函数,把负值全部变成0。 - x的尺寸不变,还是[64,128] 11. self.dropout2(x) - 随机把50%的元素置0 - droupout2 = nn.Dropout2d(0.5) - x的尺寸不变,还是[64,128] 12. self.fc2(x) - 线性变换 - fc2 = nn.Linear(128, 10) - 由[128]变成[10] - x的尺寸变为[64,10] 13. output = F.log_softmax(x, dim=1) - 归一化 - 让矩阵所有元素之和为1 - 这也是计算[负对数似然损失](#负对数似然损失)的第一步 - output的尺寸是[64,10] - 此时已经是模型输出结果,即输入的图片对应10个数字的概率。 标签: mnist, 神经网络 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭