pytorch例程2:词级语言模型 2020-08-14 笔记 暂无评论 2241 次阅读 [TOC] # 下载全部pytorch例程 访问:[Github地址](https://github.com/pytorch/examples) 或者直接下载:[examples-master.zip](https://www.proup.club/usr/uploads/2020/08/615186327.zip) 本文使用的例程,在word_language_model文件夹里。 # 一句话介绍语言模型 参考:[深入理解语言模型 Language Model](https://zhuanlan.zhihu.com/p/52061158) 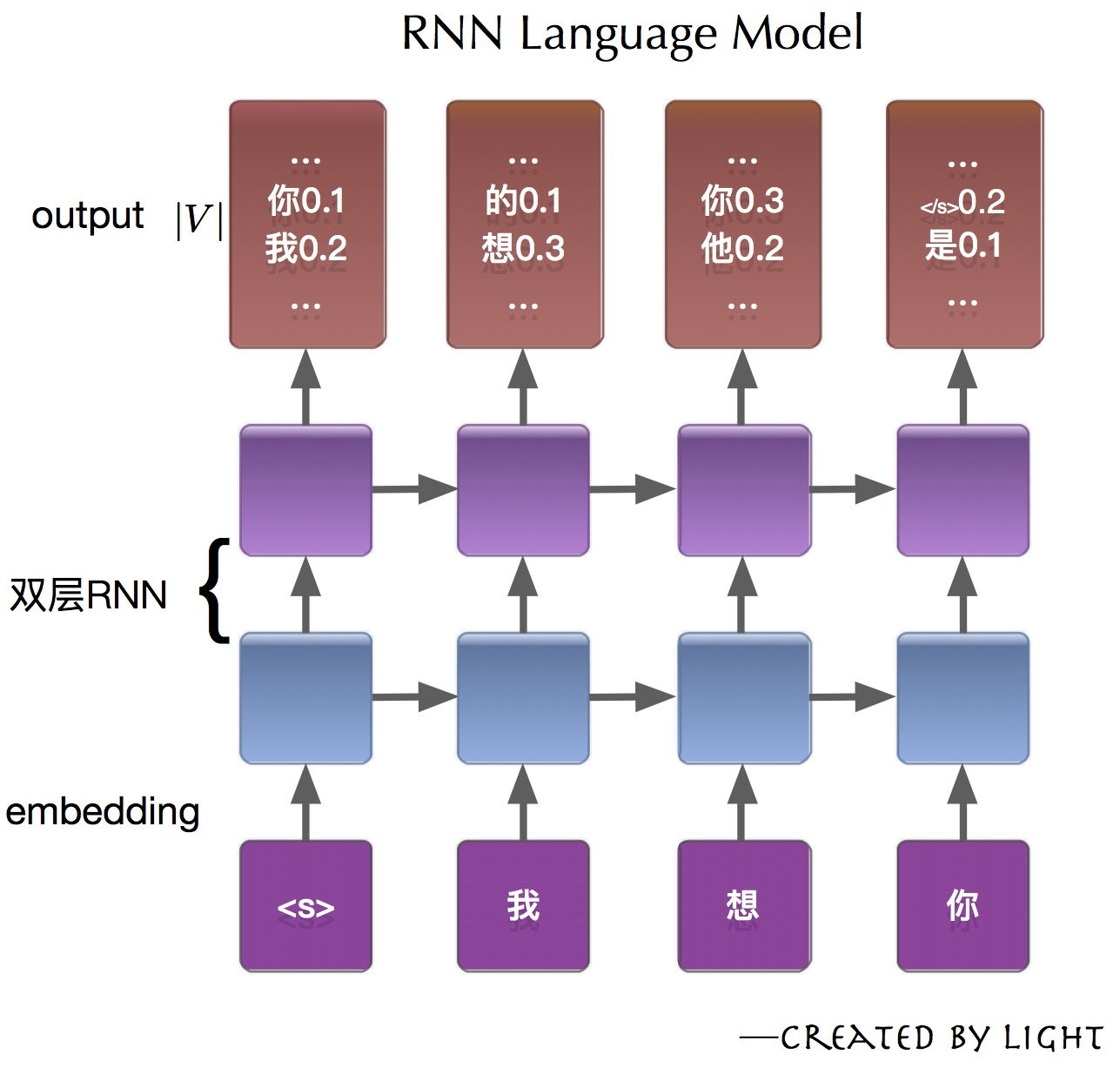 判断一个语言序列是否是正常语句,即是否是人话。 # LSTM模型 ## 什么是LSTM模型 参考:[【译】理解LSTM(通俗易懂版)](https://www.jianshu.com/p/95d5c461924c) ### LSTM用来干什么 **LSTM网络是特殊的RNN网络,用来处理序列化的数据。** - [mnist模型](https://www.proup.club/index.php/archives/378/)针对的是**独立**的数据。 - 模型看新图片时,只看这一张,不回想之前的图片。 - LSTM和RNN针对的是**序列化**的数据 - 模型看新图片时,要回想之前的图片。 - RNN(Recurrent Neural Networks,循环神经网络) - 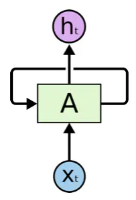 -  - 不会保存完整的输入记录,而是要提炼信息。 - 提炼过的信息,会加上这次的输入,再次提炼。 - 间隔的越久,被提炼次数就越多,信息就越不完整。 - 导致**长期记忆失效**,也就是**长依赖问题**。 - LSTM(Long Short Term Memory networks)长短期记忆网络 - 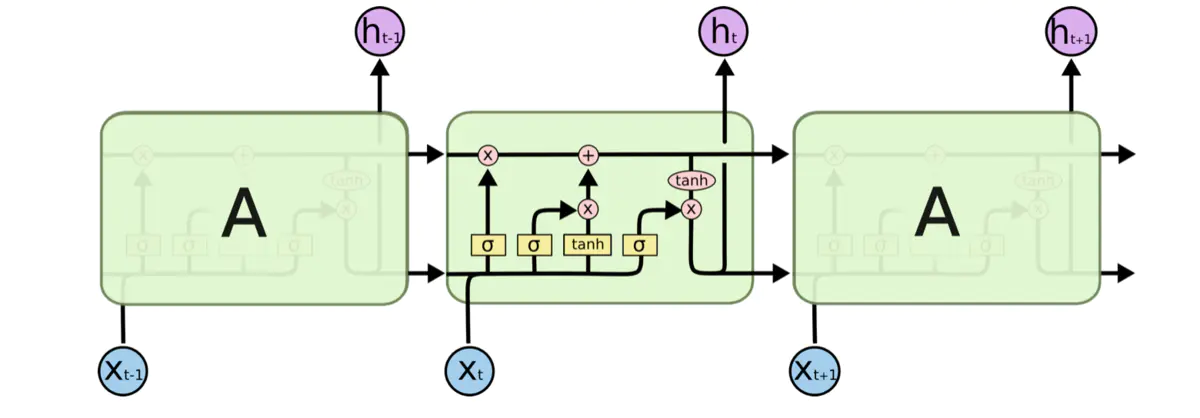 ### RNN、LSTM、MNIST - 标准RNN网络 - 网络层: - tanh(1个) - 取值范围[-1,1] - 给细胞添加新信息 - LSTM网络 - 网络层: - tanh(1个) - sigmoid(3个) - 取值范围(0,1) - 让细胞丢弃一些信息 - mnist - 网络层: - 卷积层(2个) - relu(3个) - 池化层(1个) - 丢弃层(2个) - flatten层(1个)(压平) - 线性层(2个) - softmax层(1个)(归一化) #### 三种激活函数 参考:[激活函数(Sigmoid, tanh, Relu)](https://blog.csdn.net/weixin_41417982/article/details/81437088) #### tanh 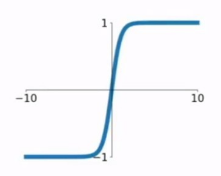 $$tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$$ #### sigmoid 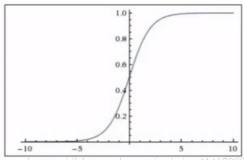 $$ \sigma(x)=\frac{1}{1+e^{-x}} $$ #### relu  $$ relu(x) = max(0,x) $$ ## 运行例程 使用命令: ``` python main.py --cuda --epochs 6 # Train a LSTM on Wikitext-2 with CUDA ``` 第一次轮结果: ``` | epoch 1 | 200/ 2983 batches | lr 20.00 | ms/batch 33.88 | loss 7.62 | ppl 2044.72 | epoch 1 | 400/ 2983 batches | lr 20.00 | ms/batch 26.72 | loss 6.85 | ppl 946.26 | epoch 1 | 600/ 2983 batches | lr 20.00 | ms/batch 26.62 | loss 6.49 | ppl 656.40 | epoch 1 | 800/ 2983 batches | lr 20.00 | ms/batch 26.59 | loss 6.30 | ppl 543.88 | epoch 1 | 1000/ 2983 batches | lr 20.00 | ms/batch 26.71 | loss 6.15 | ppl 468.73 | epoch 1 | 1200/ 2983 batches | lr 20.00 | ms/batch 26.61 | loss 6.06 | ppl 430.51 | epoch 1 | 1400/ 2983 batches | lr 20.00 | ms/batch 27.49 | loss 5.95 | ppl 384.09 | epoch 1 | 1600/ 2983 batches | lr 20.00 | ms/batch 26.70 | loss 5.96 | ppl 385.78 | epoch 1 | 1800/ 2983 batches | lr 20.00 | ms/batch 27.14 | loss 5.82 | ppl 335.76 | epoch 1 | 2000/ 2983 batches | lr 20.00 | ms/batch 26.90 | loss 5.79 | ppl 326.69 | epoch 1 | 2200/ 2983 batches | lr 20.00 | ms/batch 26.72 | loss 5.67 | ppl 290.09 | epoch 1 | 2400/ 2983 batches | lr 20.00 | ms/batch 26.91 | loss 5.67 | ppl 290.75 | epoch 1 | 2600/ 2983 batches | lr 20.00 | ms/batch 26.84 | loss 5.65 | ppl 284.16 | epoch 1 | 2800/ 2983 batches | lr 20.00 | ms/batch 26.88 | loss 5.53 | ppl 253.31 ----------------------------------------------------------------------------------------- | end of epoch 1 | time: 84.43s | valid loss 5.52 | valid ppl 249.70 ----------------------------------------------------------------------------------------- ``` 第二轮结果: ``` ----------------------------------------------------------------------------------------- | epoch 2 | 200/ 2983 batches | lr 20.00 | ms/batch 26.97 | loss 5.54 | ppl 254.84 | epoch 2 | 400/ 2983 batches | lr 20.00 | ms/batch 27.13 | loss 5.52 | ppl 249.75 | epoch 2 | 600/ 2983 batches | lr 20.00 | ms/batch 27.00 | loss 5.36 | ppl 211.74 | epoch 2 | 800/ 2983 batches | lr 20.00 | ms/batch 27.05 | loss 5.37 | ppl 215.50 | epoch 2 | 1000/ 2983 batches | lr 20.00 | ms/batch 27.08 | loss 5.34 | ppl 207.87 | epoch 2 | 1200/ 2983 batches | lr 20.00 | ms/batch 27.00 | loss 5.33 | ppl 205.84 | epoch 2 | 1400/ 2983 batches | lr 20.00 | ms/batch 27.78 | loss 5.32 | ppl 204.52 | epoch 2 | 1600/ 2983 batches | lr 20.00 | ms/batch 27.51 | loss 5.38 | ppl 217.86 | epoch 2 | 1800/ 2983 batches | lr 20.00 | ms/batch 27.16 | loss 5.25 | ppl 191.50 | epoch 2 | 2000/ 2983 batches | lr 20.00 | ms/batch 26.86 | loss 5.27 | ppl 193.53 | epoch 2 | 2200/ 2983 batches | lr 20.00 | ms/batch 27.00 | loss 5.17 | ppl 176.00 | epoch 2 | 2400/ 2983 batches | lr 20.00 | ms/batch 27.15 | loss 5.20 | ppl 181.39 | epoch 2 | 2600/ 2983 batches | lr 20.00 | ms/batch 27.27 | loss 5.21 | ppl 183.40 | epoch 2 | 2800/ 2983 batches | lr 20.00 | ms/batch 26.91 | loss 5.12 | ppl 167.79 ----------------------------------------------------------------------------------------- | end of epoch 2 | time: 83.95s | valid loss 5.29 | valid ppl 197.45 ----------------------------------------------------------------------------------------- ``` 最后一轮(第六轮)训练结果 ``` | epoch 6 | 200/ 2983 batches | lr 20.00 | ms/batch 27.96 | loss 4.78 | ppl 118.53 | epoch 6 | 400/ 2983 batches | lr 20.00 | ms/batch 28.73 | loss 4.80 | ppl 121.20 | epoch 6 | 600/ 2983 batches | lr 20.00 | ms/batch 28.60 | loss 4.62 | ppl 101.40 | epoch 6 | 800/ 2983 batches | lr 20.00 | ms/batch 28.52 | loss 4.68 | ppl 107.91 | epoch 6 | 1000/ 2983 batches | lr 20.00 | ms/batch 28.91 | loss 4.69 | ppl 108.60 | epoch 6 | 1200/ 2983 batches | lr 20.00 | ms/batch 29.91 | loss 4.69 | ppl 109.17 | epoch 6 | 1400/ 2983 batches | lr 20.00 | ms/batch 27.66 | loss 4.73 | ppl 113.70 | epoch 6 | 1600/ 2983 batches | lr 20.00 | ms/batch 27.39 | loss 4.81 | ppl 122.49 | epoch 6 | 1800/ 2983 batches | lr 20.00 | ms/batch 27.55 | loss 4.69 | ppl 108.98 | epoch 6 | 2000/ 2983 batches | lr 20.00 | ms/batch 27.52 | loss 4.73 | ppl 112.97 | epoch 6 | 2200/ 2983 batches | lr 20.00 | ms/batch 27.95 | loss 4.62 | ppl 101.40 | epoch 6 | 2400/ 2983 batches | lr 20.00 | ms/batch 27.93 | loss 4.67 | ppl 106.23 | epoch 6 | 2600/ 2983 batches | lr 20.00 | ms/batch 27.90 | loss 4.69 | ppl 108.62 | epoch 6 | 2800/ 2983 batches | lr 20.00 | ms/batch 28.60 | loss 4.63 | ppl 102.29 ----------------------------------------------------------------------------------------- | end of epoch 6 | time: 87.03s | valid loss 5.05 | valid ppl 155.55 ----------------------------------------------------------------------------------------- ``` 测试结果: ``` ========================================================================================= | End of training | test loss 4.99 | test ppl 146.62 ========================================================================================= ``` # 看结果 [epoch](https://www.proup.club/index.php/archives/378/#Epoch):用尽全部训练集的一个训练周期 [batch](https://www.proup.club/index.php/archives/378/#Batch):把训练集样本分批送给模型的一批。 [lr](https://www.proup.club/index.php/archives/378/#3.2%20scheduler%E6%98%AF%E5%B9%B2%E4%BB%80%E4%B9%88%E7%9A%84):学习率。 > optimizer优化器,是batch与batch之间的 > lr_scheduler学习率调度器,是epoch与epoch之间的 [loss](https://www.proup.club/index.php/archives/378/#2.2%20Loss):平均损失。 本例程用的也是[nll_loss,负对数似然损失](https://www.proup.club/index.php/archives/378/#%E8%B4%9F%E5%AF%B9%E6%95%B0%E4%BC%BC%E7%84%B6%E6%8D%9F%E5%A4%B1) - 负对数似然损失 1. 数据归一化(变成0~1之间的数字,总和为1) 2. 取对数 3. 取负值 ## ppl 困惑度 例程中ppl的计算公式: $$ ppl = e^{loss}$$ loss是一个batch中的损失的平均值。 ## valid loss和test loss valid loss和test loss其实都是**测试**的损失。 区别仅在于测试数据不同。 不像MNIST里,把数据集分成两份:train、test 这里是把数据集分成三份:train、valid、test [train比test多了什么](https://www.proup.club/index.php/archives/378/#3.1%20train%E6%AF%94test%E5%A4%9A%E4%BA%86%E4%BB%80%E4%B9%88) - 对train数据集,当然调用train()函数 - 先用`model.train()`把模型设成“训练模式” - 对于valid和test数据集,调用的都是evalute()函数 - evalute()函数和MNIST例程的test()函数一样 - 先用`model.eval()`把模型设成“评估模式” - 后面用`with torch.no_grad():`括起来 语言模型的训练、测试的流程,是这样安排的: - 在每个Epoch内:用**train数据**训练,用**valid数据**评估 - 当达到设定的Epoch周期数:用**test数据**做一次评估 # 看过程 ## 制作数据集 ### 原始数据(txt文本) 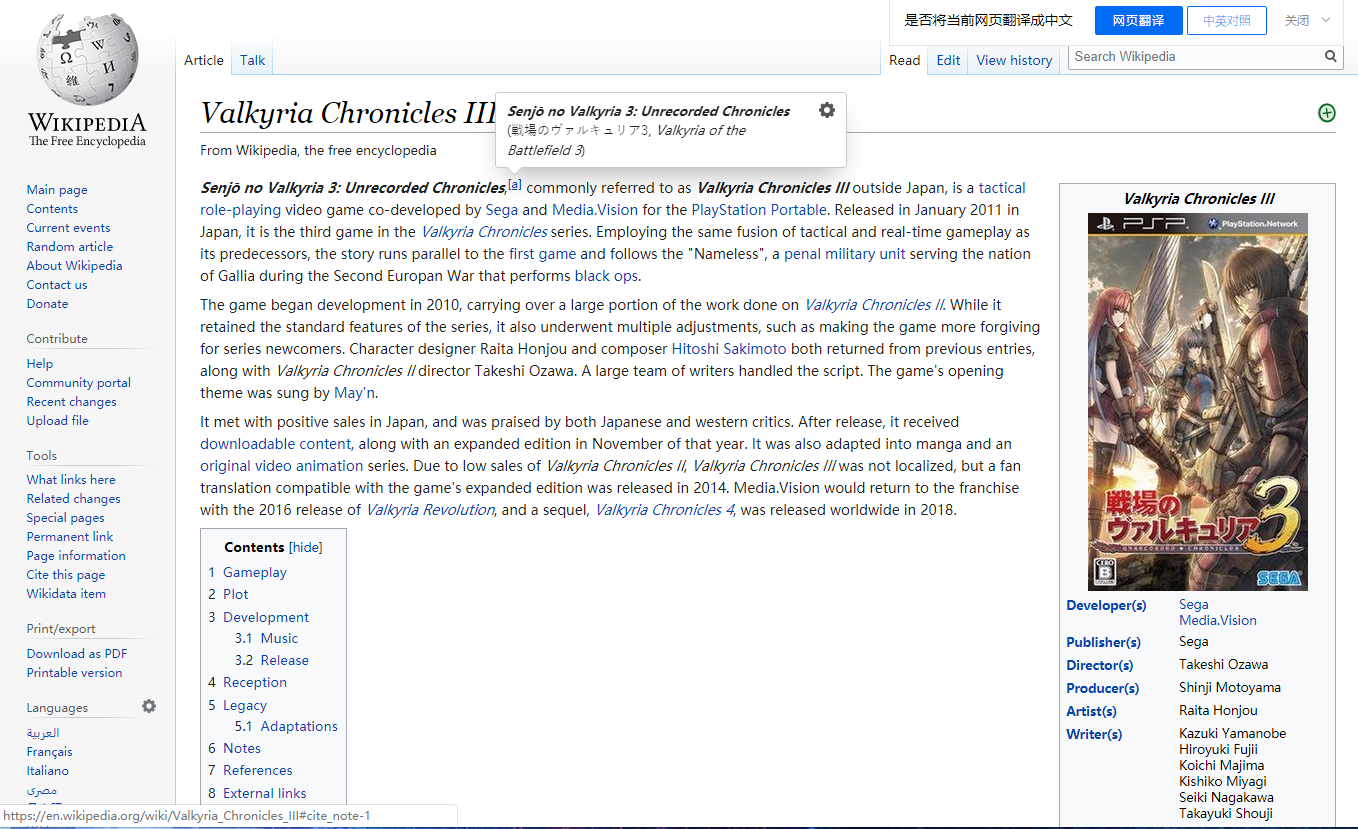 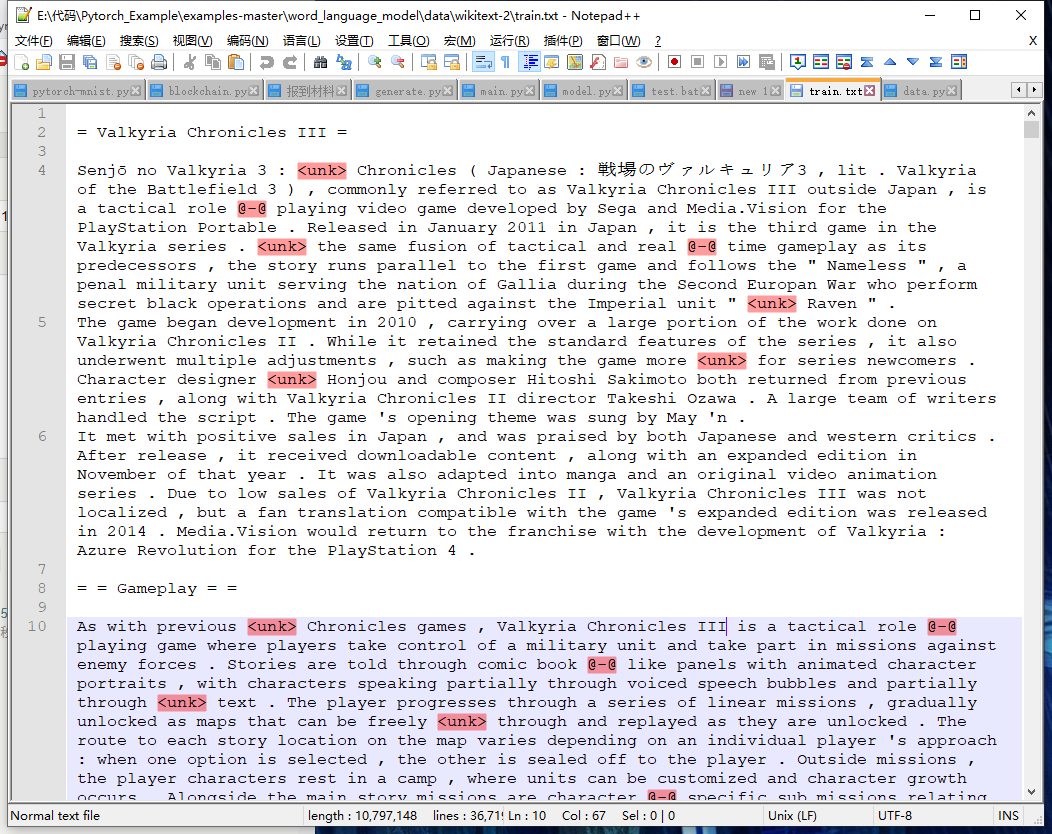 原始数据是txt文档,内容来源于维基百科,有些词被替换成了`<unk>`,符号`-`被替换成了`@-@`。 这其实是 [WikiText-2数据集](https://www.salesforce.com/products/einstein/ai-research/the-wikitext-dependency-language-modeling-dataset/) 类似的还有WikiText-103: 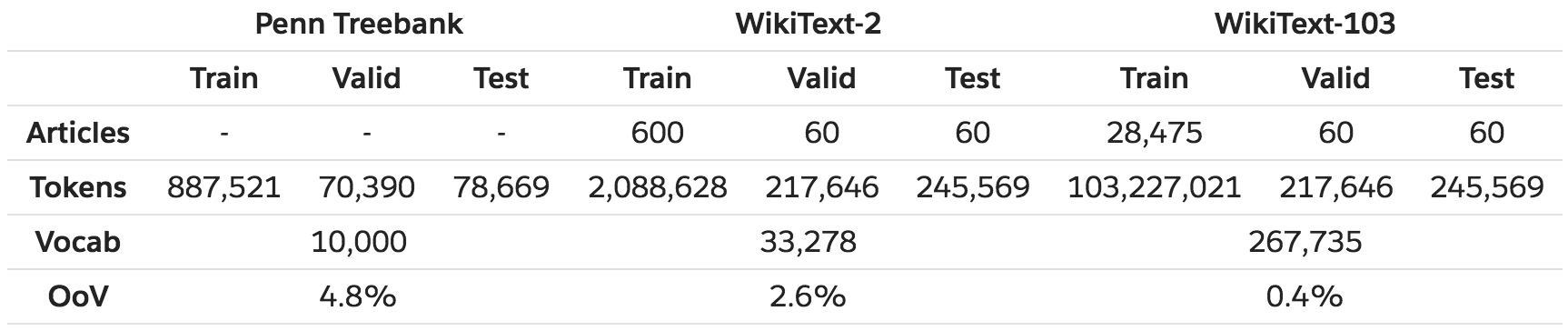 - Articles:文章数 - Tokens:共多少个词(含重复的) - Vocab:共多少个词(不包含重复的) - Oov:有多少词被替换成了`<unk>` ### 单词转数字(标记化) 用来标记化文本文件的类,叫“Corpus”,中文叫“语料库”。 - Corpus类 - 成员对象:dictionary - 用来实现**单词**与**数字**的相互映射 - 根据数字查单词 - 根据单词查数字 - 成员数组:train,valid,test - 是把原始数据逐**单词**转成**数字**以后的数组。 - 换行符号用`<eos>`表示。 词典(Corpus.dictionary)是: ``` ['<eos>', '=', 'Valkyria', 'Chronicles', 'III', 'Senjō', ... ] ``` train.txt的开头是: ``` = Valkyria Chronicles III = ``` 那么Corpus.train就是`[0, 1, 2, 3, 4, 1, 0, ...]` **标记化后得到:** - 字典dictionary - 长度33278的字典 - 训练语料train - 长度2088628的一维整型数组 - 测试语料valid - 长度217646的一维整型数组 - 测试语料test - 长度245569的一维整型数组 ### 分批(batchs化) 参考: [torch.narrow](https://pytorch.org/docs/stable/generated/torch.narrow.html) [torch.Tensor.view](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.view) [torch.reshape](https://pytorch.org/docs/stable/generated/torch.reshape.html) [torch.Tensor.contiguous](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.contiguous) - tensor.narrow(input, dim, start, length) → Tensor - 返回一个**收缩**后的tensor - 返回的tensor和原tensor共用相同的存储 - input (Tensor) 原tensor - dim (int) 要收缩第几维 - start (int) 从下标几开始 - length (int) 收缩成多长 - tensor.view(\*shape) - 返回tensor的视图,数据与原tensor数据一样,但形状不一样 - tensor.view.contiguous() - 在连续内存弄一个新的tensor,内容与view一样 - tensor.view(\*shape).contiguous()就等于tensor.reshape(\*shape) - tensor.t() - 转置矩阵 例如处理训练数据train,设置Batch-Size是20。 训练数据train的长度是2088628,不是整数,要是切成20一段、20一段的话,会有多余的。要把多余的去掉。 词级语言建模的目的,是从前往后**预测下一个单词**。 把原始文章的结尾砍掉,对这个目的影响不大。 **batchs化后得到:** - 训练数据train - 尺寸为[104431, 20]的tensor - 测试数据valid - 尺寸为[21764, 10]的tensor - 测试数据test - 尺寸为[24556, 10]的tensor 其中,每一列代表一个序列。 如果原始数据是: ``` [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104]) ``` 如果batch-size设置为5,也就是5列,那么经过batch化后得到: ``` [[ 1, 21, 41, 61, 81], [ 2, 22, 42, 62, 82], [ 3, 23, 43, 63, 83], [ 4, 24, 44, 64, 84], [ 5, 25, 45, 65, 85], [ 6, 26, 46, 66, 86], [ 7, 27, 47, 67, 87], [ 8, 28, 48, 68, 88], [ 9, 29, 49, 69, 89], [ 10, 30, 50, 70, 90], [ 11, 31, 51, 71, 91], [ 12, 32, 52, 72, 92], [ 13, 33, 53, 73, 93], [ 14, 34, 54, 74, 94], [ 15, 35, 55, 75, 95], [ 16, 36, 56, 76, 96], [ 17, 37, 57, 77, 97], [ 18, 38, 58, 78, 98], [ 19, 39, 59, 79, 99], [ 20, 40, 60, 80, 100]]) ``` 相当于从txt文档的5处位置同时出发,往后走。 ### 模型输入(data,target) 参数bptt(序列长度)决定每个batch里有多少行,也就是每条序列里有多少个单词。 有点类似于滑动窗口,窗口长度就是序列长度; 不同的是每次滑动长度不是1,而是序列长度。 用刚才1~100的例子,设置序列长度为5,那么: 第一个batch: ``` data=tensor([[ 1, 21, 41, 61, 81], [ 2, 22, 42, 62, 82], [ 3, 23, 43, 63, 83], [ 4, 24, 44, 64, 84], [ 5, 25, 45, 65, 85]]) target=tensor([ 2, 22, 42, 62, 82, 3, 23, 43, 63, 83, 4, 24, 44, 64, 84, 5, 25, 45, 65, 85, 6, 26, 46, 66, 86]) ``` 第二个batch: ``` data=tensor([[ 6, 26, 46, 66, 86], [ 7, 27, 47, 67, 87], [ 8, 28, 48, 68, 88], [ 9, 29, 49, 69, 89], [10, 30, 50, 70, 90]]) target=tensor([ 7, 27, 47, 67, 87, 8, 28, 48, 68, 88, 9, 29, 49, 69, 89, 10, 30, 50, 70, 90, 11, 31, 51, 71, 91]) ``` data中,每个位置的target,就是这个位置的下一行的元素。 ## 模型的向前传播 ### data - data - 模型的输入序列 - 是尺寸为[35,20]的tensor - 35是参数:bptt(序列长度) - 每个序列有35个单词 - 20是参数:batch_size - 20个序列同时预测 - 元素是0~33277之间的整数 - 是单词在字典上的索引值 - 字典共有33278个单词 ### target - target - 输入序列的预测目标 - 即每个单词后的一个单词 - 是尺寸为[700]的tensor - 输入序列有35\*20=700个单词, - 要预测输入序列每个单词的下一个单词,也是700个 - 元素是0~33277之间的整数 - 是单词在词典上的索引值 - 词典共有33278个单词 ### output - output - 是模型的预测结果 - 是尺寸为[700,33278]的tensor - 要预测出来700个单词 - 输入序列有35\*20=700个单词 - 要预测输入序列每个单词的下一个单词,也是700个 - 预测一个单词,有33278个可能的结果 - 词典共有33278个单词 - 元素是小于0的小数 - 参考[负对数似然损失](https://www.proup.club/index.php/archives/378/#%E8%B4%9F%E5%AF%B9%E6%95%B0%E4%BC%BC%E7%84%B6%E6%8D%9F%E5%A4%B1) - 概率矩阵x经过归一化、取对数、取负数,就成了损失值矩阵。 - 确实有一个[700,33278]的概率矩阵x - 把概率矩阵x用`log_softmax()`进行归一化、取对数。 - 此时就是output - 取负数,是在计算损失值的`nn.NLLLoss()`里实现的。 - `grad_fn=<LogSoftmaxBackward>` ### hidden - hidden - 是隐藏层 - 相当于神经元的**记忆** - 是一个“由两个尺寸为[2,20,200]的tensor组成的”元组 - 两个是因为LSTM模型 - 别的模型直接是一个tensor - 只有LSTM模型是两个tensor的元组 - 2是参数:nlayers(层数) - 20是参数:batch_size - 200是参数:nhid(每层的隐藏单元数) - 元素为小数,有正有负 - `grad_fn=<CudnnRnnBackward>` ### 模型的参数 | 参数名 | 尺寸 | | ------- | ------ | | encoder.weight | torch.Size([33278, 200])| | rnn.weight_ih_l0 | torch.Size([800, 200]) | | rnn.weight_hh_l0 | torch.Size([800, 200]) | | rnn.bias_ih_l0 | torch.Size([800]) | | rnn.bias_hh_l0 | torch.Size([800]) | | rnn.weight_ih_l1 | torch.Size([800, 200]) | | rnn.weight_hh_l1 | torch.Size([800, 200]) | | rnn.bias_ih_l1 | torch.Size([800]) | | rnn.bias_hh_l1 | torch.Size([800]) | | decoder.weight | torch.Size([33278, 200])| | decoder.bias | torch.Size([33278]) | #### 模型的第二个输入(输出) 一般的模型只需要一个输入就够了。 像MNIST模型的 [从模型输入到模型输出](https://www.proup.club/index.php/archives/378/#%E4%BB%8E%E6%A8%A1%E5%9E%8B%E8%BE%93%E5%85%A5%E5%88%B0%E6%A8%A1%E5%9E%8B%E8%BE%93%E5%87%BA) 可以看到`def forward(self, x):`,只有一个输入,x。 x是一个tensor,这个tensor可以有很多个维度,你想给模型输入哪些东西,就把它们安排在不同维度,这样就可以用一个tensor囊括所有东西了。 输出也一样,输出一个tensor也能囊括所有东西。 而本例程的模型,可以看到:`def forward(self, input, hidden)`,也就是有两个输入:input和hidden;也有两个输出,output和hidden。 hidden是隐藏层,既是第二个输入,又是第二个输出。 -  其实从这张图也能看出来,hidden层,就是从神经元右边连向神经元左边的箭头。 ~~隐藏层没有模型参数。同样~~没有模型参数的层~~还~~有:池化层、丢弃层、变平(flatten)层 ## encoder和decoder 参考:[nn.Embedding](https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html) 先看定义: ``` self.encoder = nn.Embedding(ntoken, ninp) self.decoder = nn.Linear(nhid, ntoken) ``` - ntoken是词典的单词数 - 是33278 - ninp是参数:emsize - 词嵌入的尺寸(em代表embedding,嵌入) - 默认200 - nhid是参数:每层的隐藏单元数 - 默认200 ### embedding和encoder Embedding的文档解释: - 一个简单的查找表,用于存储固定字典和大小的嵌入项。 - 此模块通常用于存储单词嵌入并使用索引检索它们。模块的输入是一个索引列表,输出是相应的单词嵌入。 实验理解: - 嵌入前的数据([data](#data)) - 尺寸为[35,20]的tensor - 内容为0~33277之间的整数 - 经过`Embedding(33278,200)` - 词嵌入后的数据 - 尺寸为[35,20,200] - 内容为小数,有正有负 这下就知道embedding为啥叫encoder(编码器)了。 编码器能把数字8编码成00001000,来给二进制的机器使用;换成词嵌入,那就是[0,0,0,0,1,0,0,0],一个向量。 - 词嵌入和编码器不同的是,编码器编出来的结果都是整数;而词嵌入编出来的是小数。 - 这样,在设计的时候,就**不用严格考虑容量大小的问题**。 - 例如:输入值的取值范围是0~33278,那么合适的编码器必须是16位,因为15位二进制数最大是32767,小于33278;而16位二进制数最大是65535,会有3万多个空余没用到;大于16位就更浪费了。 - 另外,用编码器的话,每个单词(数字)都是独立的,彼此之间没有任何关联。用**词嵌入的话,词与词相互之间就有关联了**。 - 200个维度,关联有强有弱,有正有负,而且关联是计入模型变量的,因此优化器会优化这种关联。优化到后面,模型应该就能区分近义词、反义词之类的。 ### Embedding和Linear 参考:[embedding和linear有什么区别?](https://zhuanlan.zhihu.com/p/99114132) Embedding和Linear的作用看起来是一样的,都是把矩阵从一个尺寸映射到另一个尺寸。 **区别1:参数个数不同** 从 [模型的参数](#模型的参数) 也能看出来 Embedding是1个参数:权重 Linear是2个参数:权重,偏差 **区别2:优化器不同** Embedding的优化器只有: - optim.SGD (CUDA and CPU) - optim.SparseAdam (CUDA and CPU) - optim.Adagrad (CPU) ### 优化器的实现 [优化器](https://www.proup.club/index.php/archives/378/#%E4%BC%98%E5%8C%96%E5%99%A8)可以根据算出来的梯度,来更新模型参数。 例程中没用PyTorch自带的优化器,而是自己实现了一个。 实现代码如下: ``` torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip) for p in model.parameters(): p.data.add_(p.grad, alpha=-lr) ``` 参考:[torch.nn.utils.clip\_grad\_norm\_](https://pytorch.org/docs/stable/generated/torch.nn.utils.clip_grad_norm_.html) 参考:[add\_](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.add) - clip\_grad\_norm\_(parameters,max_norm) - parameters:模型参数 - max_norm:最大值 - 限制梯度的最大值 - 防止[梯度爆炸](https://blog.csdn.net/junjun150013652/article/details/81274958) - add\_(other,alpha) - other:要加的值 - alpha:other的缩放倍数(默认是1) ### detach() 每次把隐藏层送入模型之前,都会对隐藏层的tensor做一个detach()操作。 参考:[pytorch——计算图与动态图机制](https://blog.csdn.net/qq_37388085/article/details/102559532) 参考:[torch.Tensor.detach](https://pytorch.org/docs/stable/autograd.html#torch.Tensor.detach) 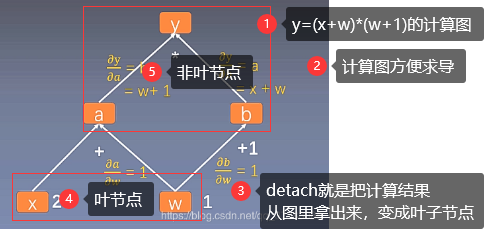 ### 调度器的实现 每个Epoch周期,都要:①用train_data进行一轮训练;②用val_data进行一轮评估,得到当前评估损失值val_loss 然后就是[调度器](https://www.proup.club/index.php/archives/378/#3.2%20scheduler%E6%98%AF%E5%B9%B2%E4%BB%80%E4%B9%88%E7%9A%84)操作的地方了: - 把当前评估损失值val_loss与最优评估损失best_val_loss进行比较 - 如果当前损失值更好: - 保存当前模型 - 更新best_val_loss - 否则: - 学习率缩小4倍 # PyTorch的RNN模型 用户定义的神经网络模型(RNNModel类),也是基于nn.Module基类,和MNIST一样。 参考:[nn.recurrent-layers](https://pytorch.org/docs/stable/nn.html#recurrent-layers) PyTorch把RNN、LSTM、GRU都封装好了。 ## RNN模型定义了哪些层 参考:[nn.init](https://pytorch.org/docs/stable/nn.init.html) 参考:[getattr](https://www.runoob.com/python/python-func-getattr.html) 从例程代码的定义顺序来看,RNN模型类,有以下几层: 1. 丢弃层 - self.drop = nn.Dropout(dropout) - 没有参数 2. 嵌入层(编码器) - self.encoder = nn.Embedding(ntoken, ninp) - 有一个参数 - encoder.weight (torch.Size([33278, 200])) 3. 循环层 - self.rnn = getattr(nn, rnn_type)(ninp, nhid, nlayers, dropout=dropout) - 这里有一个Python技巧:getattr - getattr(nn, 'GRU')就是nn.GRU - getattr(nn, 'LSTM')就是nn.LSTM - 有8个参数(因为设了两层,每层是4个) - rnn.weight_ih_lx(x是0和1torch.Size([800, 200])) - rnn.weight_hh_lx(x是0和1torch.Size([800, 200])) - rnn.bias_ih_lx(x是0和1torch.Size([800])) - rnn.bias_hh_lx(x是0和1,torch.Size([800])) 4. 线性层(解码器) - self.decoder = nn.Linear(nhid, ntoken) - 有2个参数 - decoder.weight(torch.Size([33278, 200])) - decoder.bias(torch.Size([33278])) ### RNN 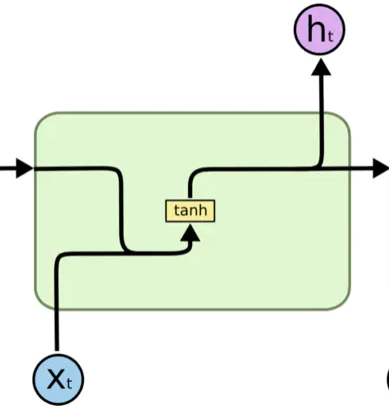 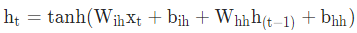 - h_t:t时刻的隐藏状态 - x_t:t时刻的输入 - h_{t-1}:前一时刻的隐藏状态,或时间是0时的初始隐藏状态 - tanh激活函数可以改成relu激活函数。 - ih代表input_hidden,输入的隐藏层 - hh代表hidden_hidden,隐藏层的隐藏层 参考:[torch.nn.RNN](https://pytorch.org/docs/stable/generated/torch.nn.RNN.html#torch.nn.RNN) - torch.nn.RNN - 参数 - input_size:x的特征数 - 例程中ninp = emsize,词嵌入的尺寸 - hidden_size:隐藏层的特征数 - 例程中的nhid,每层的隐藏单元数 - num_layers:循环层的层数 - 例程中的nlayers - 默认为1 - nonlinearity:非线性的激活函数 - 可以是:'tanh'或'relu' - 默认为'tanh' - bias:是否用偏重b_ih和b_hh - 可以是True或False - 默认为True - batch_first:决定输入输出的格式 - 若为True:(batch,seq,feature) - 若为False:(seq,batch,feature) - 默认False - dropout:在最后一层以外的每个RNN层输出后,引入一个丢失层,dropout是丢失概率 - 默认为0 (相当于没有丢失层) - bidirectional:是否变成双向RNN - 可以是True或False - 默认为False - 输入: - input - 尺寸为[seq_len,batch,input_size]的tensor - 内容是输入序列的特征 - 特征就是编码后的词向量 - h_0 - 尺寸为[num_layers * num_directions, batch, hidden_size]的tensor - 内容是隐藏状态 - 默认为零 - 例程中num_directions是1 - 如果bidirectional=True,即双向RNN,那么num_directions就是2。单向的就是1。 - 输出: - output - 尺寸为[seq_len, batch, num_directions * hidden_size]的tensor - 内容是RNN最后一层的输出特征 - h_n - 尺寸为[num_layers * num_directions, batch, hidden_size]的tensor,和输入的h_0一样 - 内容是隐藏状态 ### LSTM 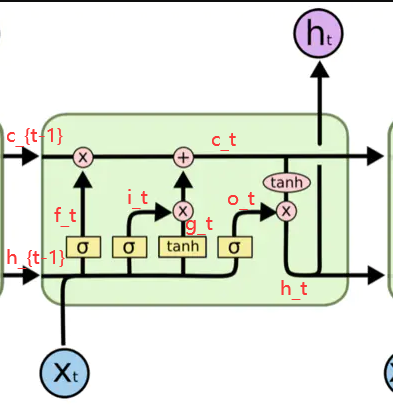 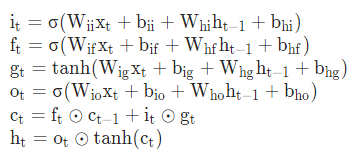 - ⊙:Hadamard product (哈达玛积,基本积) - 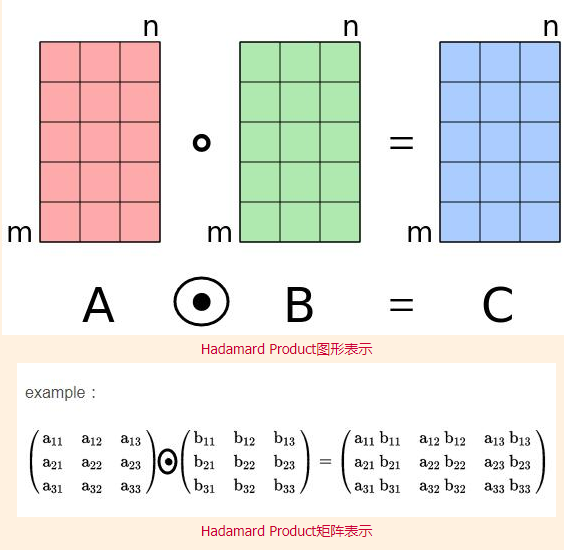 参考:[torch.nn.LSTM](https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html) - torch.nn.LSTM - 参数:和torch.nn.RNN一样 - 输入:多了一个隐藏层c_0 - h_0 - 尺寸为[num_layers * num_directions, batch, hidden_size]的tensor - 内容是细胞状态 - 默认为零 - 输出:多了一个隐藏层c_n - c_n - 尺寸为[num_layers * num_directions, batch, hidden_size]的tensor,和c_0一样 - 内容是细胞状态 ### GRU(门循环单元) 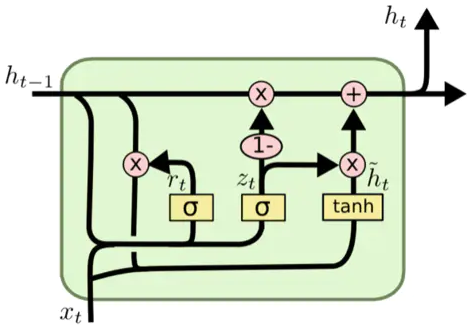 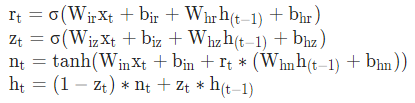 参考:[torch.nn.GRU](https://pytorch.org/docs/stable/generated/torch.nn.GRU.html) - torch.nn.GRU - 参数:与torch.nn.RNN一样 - 输入:与torch.nn.RNN一样 - 输出:与torch.nn.RNN一样 # PyTorch的TRANSFORMER模型 参考:[Transformer模型详解](https://blog.csdn.net/u012526436/article/details/86295971) ## TRANSFORMER模型有哪些层 ### PositionalEncoding (位置编码) 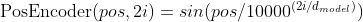 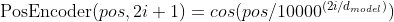 - pos:单词在句子中的位置 - i:词嵌入的位置下标 在序列中注入有关标记的相对或绝对位置的一些信息。 位置编码与嵌入的维数相同,因此可以将两者相加。 这里,我们使用不同频率的正弦和余弦函数。 **参数:** - d_model:嵌入的维度 - 即参数:emsize,词嵌入的长度(200) - dropout:丢弃值(给丢弃层用)(0.2) - 输入→编码层→丢弃层→输出 - max_len:最长序列的长度(5000) **输入:** - x:尺寸为[sequence length, batch size, embed dim]的tensor - 也就是[2,20,200],和RNN模型的词嵌入的结果一样。 **输出:** - output:尺寸为[sequence length, batch size, embed dim]的tensor - 也是[2,20,200],和RNN模型的词嵌入的结果一样。 循环神经网络是靠hidden层,来保留记忆信息。 transformer模型没有hidden层,所以用位置编码,来记住每个词的位置。 ### TransformerEncoderLayer - TransformerEncodeLayer - 参数: - d_model:词嵌入的长度 - nhead:多头部注意力模型中的头部数量(2) - dim_feedforward:隐藏层的单元数(200) - dropout:丢弃值(0.1) - activation:激活函数(默认relu) ### TransformerEncoder - TransformerEncoder - TransformerEncodeLayer是一层 - TransformerEncoder是多层 - 参数: - encoder_layer:一个TransformerEncodeLayer的实例 - num_layers:层数 - 输入: - src:送到编码器的序列 - mask:掩码,默认是None ## Transformer模型的向前运算过程 生成一个[序列长度,序列长度]的掩码,是一个“主对角线以上全是-inf,主对角线以下全是0”的上三角矩阵。 1. 输入数据经过词嵌入的编码器,乘以`sqrt(词嵌入长度)` - 输入数据的尺寸是[序列长度,batch_size] - 尺寸是[35,20] - 内容是0~33277 - 经过编码是[序列长度,batch_size,词嵌入长度] - 尺寸是[35,20,200] - 内容是小数,有正有负 2. 经过位置编码 - 词嵌入的编码多了“相对位置”的信息 - 尺寸不变 - 尺寸是[35,20,200] - 内容是小数,有正有负,有的变成了0 3. 经过transformer编码 - 尺寸不变 - 尺寸是[35,20,200] - 内容是小数,有正有负,刚才是0的现在不是0了 4. 经过线性层解码 - 此时数据尺寸是[序列长度,batch_size,词典长度] - 尺寸是[35,20,33278] - 内容是小数,有正有负 5. 归一化,取对数 - 此时就是模型的输出output 之后,取`output.argmax(dim=2, keepdim=True)`就是预测结果;取`F.nll_loss(output, target, reduction='sum').item()`就是损失值。 标签: none 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭