边缘计算与深度学习的融合 2020-08-20 笔记 暂无评论 6457 次阅读 [TOC] # 参考资料 1. [Convergence of Edge Computing and Deep Learning A Comprehensive Survey.pdf](https://www.proup.club/usr/uploads/2020/08/727572059.pdf) 2. [面向边缘人工智能计算的区块链技术综述.pdf](https://www.proup.club/usr/uploads/2020/08/2606021851.pdf) # 开始之前的想法 1. 边缘计算+深度学习,用什么架构好。 2. 感觉边缘场景不适合用区块链,为什么要用区块链。 3. 有没有什么嵌入式系统,适合用来搞边缘计算+深度学习。 # 简介 ## 边缘计算 - 边缘计算是对云计算的补充可扩展 - 边缘计算与云计算结合的优势: 1. 主干网减压(backbone network alleviation) - 减少了边缘节点与云中心的网络通信 2. 快速服务响应(agile service response) - 降低数据传输时延 - 提高响应速度 3. 强力的云备份(powerful cloud backup) - 边缘节点存不下时,存云上 ### 范例 #### Cloudlet 和 Micro Data Center 是对云计算的补充 - Cloudlet - 结合了移动计算和云计算 - 移动设备 + 微云 + 云 - 亮点: - 支持**低延迟云计算**的系统和算法 - 开源,可扩展 - Micro Data Center - 给没计算能力的设备 配一个微型的云中心 - (所有计算 + 存储 + 网络设备)==> 一个机柜 #### 雾计算 - Fog Computing - 完全分布式的多层云计算架构 - 针对特定地理范围 - 实时性很强 - 更关注物联网 #### 移动(多址)边缘计算 - Mobile (Multi-access) Edge Computing (MEC) - 在蜂窝基站上部署边缘服务器 - 低延迟、高带宽、位置感知 #### 边缘计算术语的定义 公共边缘设备 = 终端设备(end level) + 边缘节点(edge level) - 终端设备(end level) - 用于指代移动边缘设备 - 包括: - 智能手机 - 智能车辆 - 各种物联网设备 - 边缘节点(edge level) - 包括: - cloudlet - 路侧单元(Road-Side Units, RSU) - 雾节点 - 边缘服务器 - MEC(Mobile Edge Computing)服务器 #### “端边云”协作计算 - Collaborative End-Edge-Cloud Computing - 终端设备(End)生成计算任务 - 强度低的任务:由终端设备或边缘执行 - 强度高的任务:合理分割,分别调度给端、边、云。 - 好处: - 保证结果的准确性 - 减少任务的执行延迟 - 重点: - × 任务的完成 - √ 实现以下三者的最佳平衡 - 设备能耗 - 服务器负载 - 传输和执行延迟 ### 边缘计算AI硬件系统 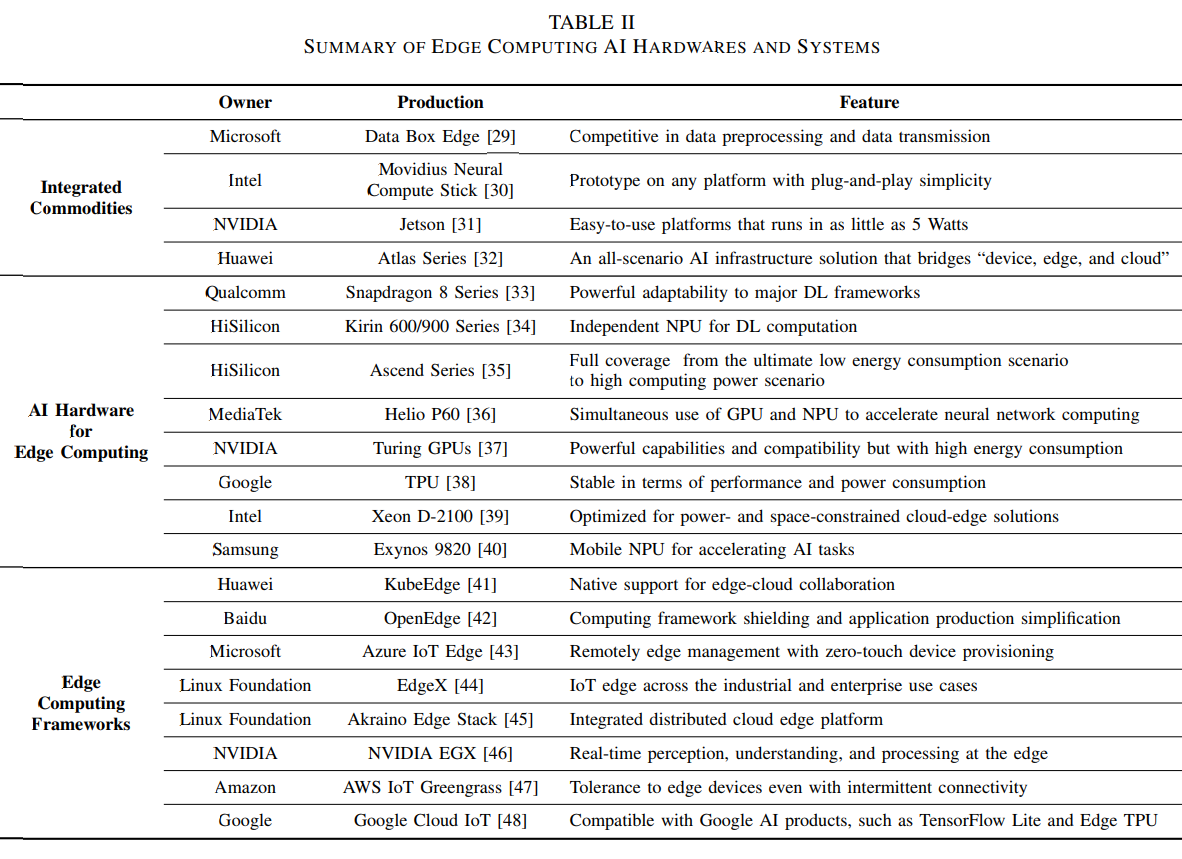 - 基于GPU的硬件 - ↑更好的兼容性和性能 - ↓会消耗更多能量 - 基于FPGA的硬件 - ↑节能,需要较少的计算资源 - ↓跟GPU相比,兼容性较差,编程能力有限 - 基于ASIC的硬件 - 通常采用定制设计 - 性能和功耗方面更稳定 #### 集成方案 | | | | | --- | --- | ---- | | Microsoft | Data Box Edge | 在数据预处理和数据传输方面具有竞争力 | | Intel | Movidius Neural Compute Stick | 任何平台上的原型,具有即插即用的简单性 | | NVIDIA | Jetson | 易于使用的平台,运行功率仅为5瓦 | | Huawei | Atlas Series | 一个连接“设备、边缘和云”的全场景人工智能基础设施解决方案 | #### AI硬件 | | | | | -- | -- | -- | |Qualcomm | Snapdragon 8 Series | 对主要DL框架的强大适应性 | |HiSilicon | Kirin 600/900 Series | 用于DL计算的独立NPU | |HiSilicon | Ascend Series | 从最终低能耗场景到高计算能力场景的全覆盖 | |MediaTek | Helio P60 | 同时使用GPU和NPU加速神经网络计算 | |NVIDIA | Turing GPUs | 功能强大,兼容性强,但能耗高 | |Google | TPU | 性能和功耗稳定 | |Intel | Xeon D-2100 | 针对功率和空间受限的云边缘解决方案进行了优化 | |Samsung | Exynos 9820 | 用于加速人工智能任务的移动NPU | #### 边缘计算框架 | | | | | -- | -- | -- | |Huawei | KubeEdge | 对边缘云协作的本机支持 | |Baidu | OpenEdge | 屏蔽计算框架与简化应用开发 | |Microsoft | Azure IoT Edge | 通过零接触设备配置进行远程边缘管理 | |Linux Foundation | EdgeX | 工业和企业使用案例中的物联网优势 | |Linux Foundation | Akraino Edge Stack | 集成分布式云边缘平台 | |NVIDIA | NVIDIA EGX | 在边缘实时感知、理解和处理 | |Amazon | AWS IoT Greengrass | 能容忍边缘设备间歇性连接 | |Google | Google Cloud IoT | 兼容谷歌人工智能产品,如TensorFlow Lite和Edge TPU | ### 边缘的虚拟化技术 1. 边缘计算资源有限 - 要最大限度利用资源 2. DL服务严重依赖于复杂的软件库 - 要能隔离不同的服务 3. 服务响应速度对于EdgeDL至关重要 - 不仅要计算能力,还要有敏捷的服务响应 - 虚拟化技术 - 虚拟机 - 能更好的隔离任务 - 更好的分配和使用空闲的计算资源 - 容器 - 更灵活 - 处理器消耗和内存占用比虚拟机显著减少 - 网络虚拟化 - 软件定义网络(SDN) - 控制面和数据面分离 - 集中可编程的控制平面 - 标准化应用程序编程接口 - 网络切片 - 允许一个公共的共享物理基础设施上创建多个网络实例,每个实例都针对特定的服务进行了优化。 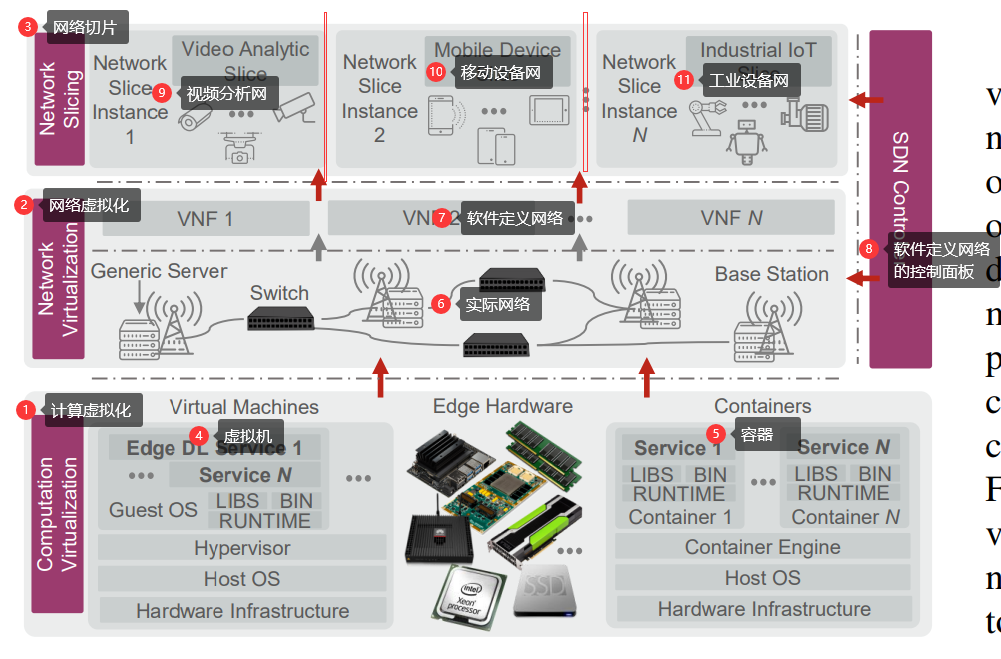 ## 深度学习(DL) - 优势领域 - 计算机视觉(CV) - 自然语言处理(NPL) - 限制因素 - 成本 - 在云中训练和使用模型 - 要传输大量数据 - 要大量网络带宽 - 延迟 - 云服务 - 没有保障 - 不满足实时(time-critical)程序的要求 - 例如:协同自主驾驶 - 可靠性 - 对很多工业场景,AI服务 - 必须高度可靠 - 断网也要能用 - 隐私 - 深度学习所需的数据可能包含大量隐私信息 - 隐私问题对智能家居和城市等领域至关重要 ### 神经网络模型(DNN)  - 全连接神经网络(FCNN) - 每一层的输出都传给下一层 - 可用于:特征提取,函数逼近 - 复杂度高、性能一般、收敛速度慢 - 自动编码器(Auto-Encoder, AE) - 是两个nn堆栈,以无监督学习的方式将输入复制到输出 - 能学习输入数据的低维有效特征来**恢复输入数据** - 可用于:分类,存储高维数据 - 卷积神经网络(CNN) - 通过使用池操作和一组不同的移动滤波器,捕捉相邻数据段之间的相关性,对输入数据进行连续的更高层次的抽象。 - 与FCNN相比: - 复杂度更小 - 过拟合的风险更小 - 可用于:处理与图像相似结构的数据 - 生成对抗网络(GAN) - 由生成器和鉴别器组成 - 生成器: - 输入:反馈 - 输出:生成的数据 - 鉴别器: - 输入:真实的数据 和 生成的数据 - 输出:分辨结果 - 好的生成器可以生成分辨不了的信息 - 循环神经网络(RNN) - 专门处理连续数据 - 每个神经元不仅从上层接收信息,还从自身的前一个信道接收信息 - 可用于:预测未来信息,恢复序列数据的缺失部分 - 严重问题是梯度爆炸 - 可以通过添加门结构,以控制信息流,来解决 - 迁移学习(Transfer Learning, TL) - 将知识从源域传递到目标域,从而在目标域获得更好的学习性能。 - 可用于:将大量计算资源所学习到的现有知识转移到新的场景中,从而加快训练过程,降低模型开发成本。 - 知识蒸馏(Knowledge Distillation) - 把知识从一个大模型迁移到一个小模型 ### 深度强化学习(DRL)  机器人做动作,与环境交互,根据观测状态做下一步动作。 旨在解决**决策问题** 可用于:机器人、金融、推荐系统、无线通信 - 基于价值的DRL - Deep Q-Learning (DQL) - 使用DNNs拟合动作值,将高维输入数据映射到动作。 - 经验重演→打破过度信息之间的相关性 - 单独建立目标网络→抑制不稳定性 - Double Deep Q-Learning (DDQL) - 可以处理DQL高估动作值的情况 - 不必了解每个状态下每个动作的效果,就可以知道那些状态是(或不是)有价值的 - 基于策略梯度的DRL - 不断计算策略期望报酬相对于他们的梯度,来更新策略参数,从而收敛到最优策略。 - DNN→将策略参数化 - 策略梯度法→优化 - 常用Actor-Critic (AC)框架 - Actor:用策略DNN更新策略 - Critic:用DNN拟合“动作-状态”的值,提供梯度信息 ### 分布式DL训练 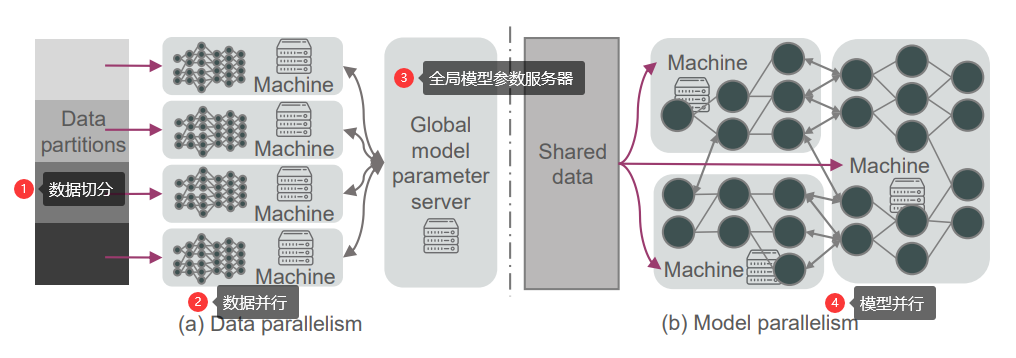 - 模型并行 - 首先将一个大的DL模型分成多个部分,用公共数据,并行地训练各自的部分模型 - 数据并行 - 将数据划分为多个分区,用各自分配的数据,并行训练模型的副本 ### 可能的边缘DL计算框架 | | CNTK | Chainer | TensorFlow | DL4J | TensorFlow Lite | MXNet | (Py)Torch | CoreML | SNPE | NCNN | MNN | Paddle-Mobile | MACE | FANN | | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | |Edge Support | × | × | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | |Android | × | × | × | √ | √ | √ | √ | × | √ | √ | √ | √ | √ | × | |iOS | × | × | × | × | × | √ | √ | √ | × | √ | √ | √ | √ | × | |Arm | × | × | √ | √ | √ | √ | √ | × | √ | √ | √ | √ | √ | √ | |FPGA | × | × | × | × | × | × | √ | × | × | × | × | √ | × | × | |DSP | × | × | × | × | × | × | × | × | √ | × | × | × | × | × | |GPU | √ | √ | √ | √ | √ | √ | √ | × | × | × | × | × | × | × | |Mobile GPU | × | × | × | × | √ | × | × | √ | √ | √ | √ | √ | √ | × | |Training Support | √ | √ | √ | √ | × | √ | √ | × | × | × | × | × | × | √ | ## 两者融合 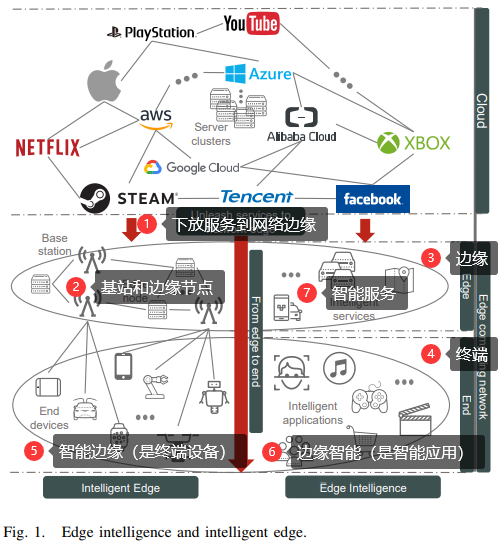 - 边缘深度学习(Edge DL) = 边缘智能(应用) + 智能边缘(设备) - 目标是边缘智能(应用)。 - 智能边缘(设备)的深度学习服务也是边缘智能(应用)的一部分 - 智能边缘(设备)可以为边缘智能(应用)提供更高的服务吞吐量和资源利用率 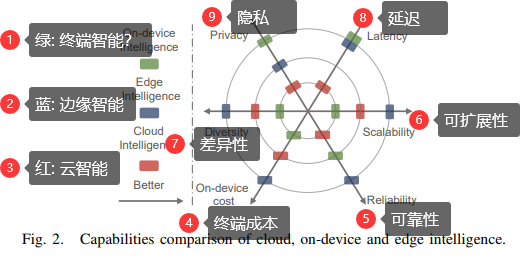 - 优点: 1. 就近DL,显著降低了延迟成本 2. 数据只传到边缘,增强了隐私保护 3. 分布式DL架构,提供了更可靠的DL计算 4. 更多数据,更多应用场景 5. 拓宽商业价值,加速发展 - Edge DL的五条关键技术: 1. 边缘上的DL应用 - 系统地组织边缘计算、提供DL智能服务的技术框架 2. 边缘上的DL预测(inference) - 重点研究DL在边缘计算体系结构中的实际部署和预测,以满足不同的需求,如精度和延迟; 3. 边缘计算 - 适配边缘计算平台的网络结构、硬件和软件,以支持DL计算; 4. 边缘上的DL训练 - 在资源和隐私约束下,在分布式边缘设备上训练边缘智能的DL模型 5. 用于优化边缘的DL - 用于维护和管理边缘计算网络(系统)不同功能的DL的应用,例如边缘缓存,计算任务下放。 - 一个边缘节点要有两种DL模型 - 一个是向外提供智能服务的 - 一个是自动维护边缘的  - 用于提供DL服务的边缘计算 - 边缘硬件 - EdgeDL的通信和计算方式 - 移动CPU和GPU - 整体下放 - 横向合作 - FPGA的解决方案 - 部分下放 - 纵向合作 - 为DL定制的边缘框架 - EdgeDL的性能评估 - 边缘上的DL训练 - 边缘上的分布式训练 - 联邦学习 - Vanilla Federated Learning - Communication-efficient FL - Resource-optimized FL - Security-enhanced FL - 边缘上的DL预测(inference) - DL模型的优化 - DL模型的分割 - 提前退出预测 - DL计算的共享 - 边缘上的DL应用 - 实时视频分析 - 智能家庭和城市 - 智能制造 - 自主车联网 - 用于优化边缘的DL - 自适应边缘缓存 - 优化 边缘的任务 - 边缘的管理和维护 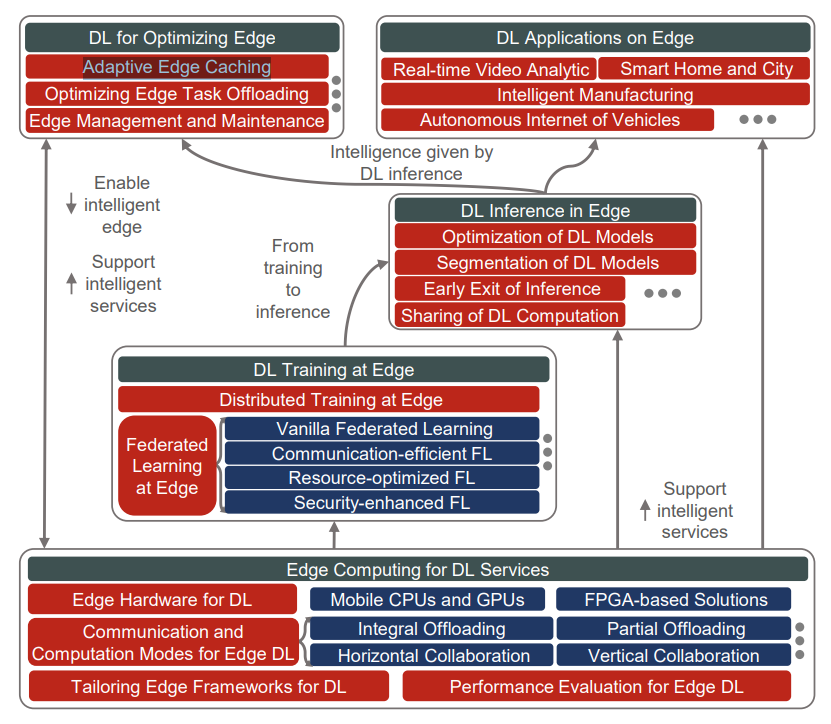 # 边缘上的DL应用 - “端云”架构 - 部署DL应用到云计算中心 - 原因:大部分DL模型很复杂,“资源有限的”设备难以计算。 - 劣势: - 实时性差 - “端边云”架构 - 部署DL应用到边 - 能够: - 增加DL应用场景 - 低延迟 ## 实时视频分析 应用场景:自动绘图,VR,AR,智慧监控等 需要:高算力,大量存储资源 不适合云计算的原因:高带宽消费,延迟不稳定,可靠性不好。 解决办法:在数据源旁边(终端设备、边缘节点)进行视频分析,与云互补 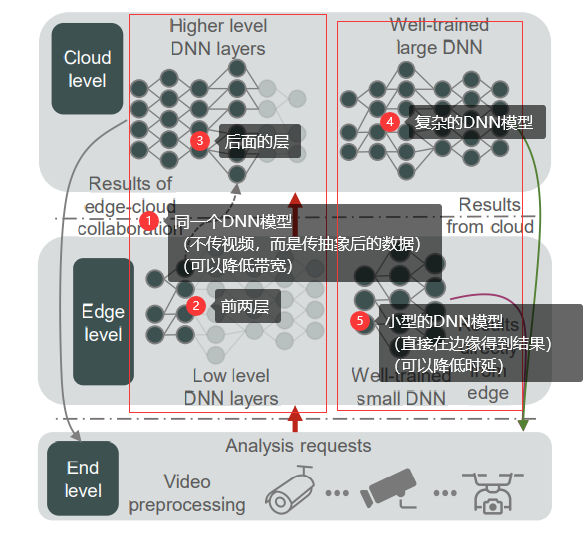 - 终端 - 设备: - 智能手机 - 监控摄像头 - 负责: - 视频捕捉 - 多媒体数据压缩 - 图像预处理 - 图像分割 - 策略: - 权衡视频压缩与: - 网络情况 - 数据使用 - 电池消耗 - 处理时延 - 帧率 - 分析的准确率 - 多租户(multi-tenant)DL: - NestDNN - 通过修剪和恢复方案,将DL模型转为一组后代模型 - 资源需求较少等模型,与资源需求较多等模型,共享其模型参数 - 边端 - 是分布式的,数量众多,彼此合作,以提供更好的服务 - LAVEA - 将边缘节点连接到相同的接入点或BS以及终端设备 - 确保服务可以像互联网访问一样无处不在 - 在边缘处压缩DL模型,可以提高整体性能 - 例如减少CNN层中不必要的滤波层 - 边缘服务框架EdgeEye - 实现了基于DL的高度抽象的实时视频分析功能 - VideoEdge - 实现了“端边云”层次架构 - 保持了高分析精度,同时实现分析任务的负载均衡 - 云端 - 负责在边缘层之间集成DL模型,并更新边缘节点上分布式DL模型的参数 - 局部影响全局问题:云端需要整合不同的好的DL模型 - 边端无法自信的提供服务时: - 用云端的计算能力和全局知识做进一步处理 - 帮助边缘节点更新DL模型 ## 自主车联网(IoVs) 由于IoVs系统涉及到多维控制,首先采用基于DRL(深度强化学习)的方法。 ## 智能制造 - 智能制造时代的两个最重要原则: - 自动化 - 是主要目标 - 数据分析 - 是最有用的工具 - 智能工厂中的边缘计算 - 有助于将云的计算资源、网络带宽和存储容量扩展到物联网边缘 - 实现生产过程中的资源调度和数据处理 - DeepIns - 用DL和边缘计算,来保证性能和时延 - 主要思想: - 将用于检测的DL模型进行划分,分别部署到端、边、云 - IoT边缘的挑战 - 如何远程管理和评估模型 - 学习复杂事件的框架 - 缓存、与异构物联网设备的通信、计算卸载,三者结合到一起 ## 智慧家庭和城市 - 分层分布式边缘计算架构 - 能支持中大规模基础设施组件和服务的集成 - 终端:对延迟敏感的应用程序 - 边端:稍微容忍延迟的任务 - 云端:负责深度分析的大规模DL模型 - DL还可用于: - 组织和调度基础设施 - 实现城市区域或城市之间的整体负载平衡和资源优化利用 # 边缘的DL推理(预测) ## 优化DL模型 模型冗余在DNN中很常见,因此优化模型是可能的。 - 优化的方法 - 转换或重新设计DL模型 - 使其适合于边缘设备 - 尽可能减少模型性能的损失 ### 针对资源相对充足的边缘节点的优化方法 - 以常数级的计算开销,来增加DL模型的深度和宽度 - 例如CNN的inception和deep residual networks(深残差网络) - 对于更一般的神经网络结构: - 参数修剪和共享,包括权重量化 - 低秩分解 - 转移/压缩卷积滤波器 - 知识提炼 ### 针对资源预算紧张的终端设备的细粒度优化方法 - 模型输入 - 每个应用场景都有不同的优化空间 - 对象检测: - FFSVA使用两个前置流专用滤波器 - YOLO过滤大量但“非目标对象”帧 - Chameleon利用视频输入的时间和空间相关性,来节省搜索**最佳模型配置**的成本 - 例如帧分辨率和采样率 - Region-of-Interest(RoI)把目标对象从帧画面中裁剪出来 - 模型结构 - 广义DNN结构,在保持精度的同时降低开销: - 点态群卷积和信道洗牌(point-wise group convolution and channel shuffle) - 并行卷积和池计算( paralleled convolution and pooling computation) - 深度方向可分离卷积(depth-wise separable convolution) - NoScope - 用两种模型来代替标准模型 - 专用模型,放弃标准模型的概括性,以换取更快的推论 - 差别检测器,识别输入数据中的临时差别 - 最大化DL服务的吞吐量 - 级联这两个模型 - 基于开销,优化模型的架构和阈值 -  - 模型选择 - 选模型,需要权衡精度和推理时间 - kNN - 自动构建预测器 - 由“按顺序排列”的DL模型组成 - 由预测器和自动调整的模型输入的特征,来选择模型 - 压缩DL模型 - 结合不同的压缩技术(例如模型修剪) - 按性能和资源需求,来折中 - AdaDeep - 基于DRL,自动选择压缩技术,组建压缩的模型 - 模型框架 - 价值: - 提供优化过的软件内核库,来允许部署DL - 寻找最少的非冗余元素,来自动压缩DL模型 - 对所有常用的DL结构执行量化和编码 - 将DL模型专门用于上下文,并跨多个同时执行的DL模型共享资源 - 支持在单片SRAM上运行DL模型,因为运行在SRAM上比运行在DRAM上更省电 ## 分割DL模型 DL模型要分割成多个分区,然后分配给: 1. 终端设备上的异构本地处理器(如gpu、cpu) 2. 分布式边缘节点 3. 协作端边缘云架构 ### 横向分割模型 - 是最常见的方法。 - 挑战:如何智能选择分割点 - 选择分割点的步骤 1. 评估不同DNN层的资源成本和层与层之间数据的大小; 2. 根据具体的层配置和网络带宽预测总成本; 3. 根据延迟、能量需求等从候选划分点中选择最佳的。 ### 纵向分割模型 将层融合,并以网格的方式进行垂直分区,从而将CNN层划分为可独立分布的计算任务。 ## 提前退出推理(EEoI) 有的数据推理的慢(推到最后才出结果),有的数据推理得快(推到中间就知道结果了) 如果对某些分支具有高度的信心,就可以提前退出。  EEoI不应被视为独立于模型优化和模型分割 ## 共享的DL计算 同一个时空的用户,可能会对同一个区域申请进行目标检测,可能造成计算冗余。 - 缓存 - 在边缘节点缓存CNN层的内部数据 - 通过调整缓存大小,来最小化端到端的时延 - 基于帧相似度 - 对“第一人称视角”视频的连续帧 - 复用前一帧的计算结果到当前帧 ### 从缓存中找可复用的结果 缓存框架系统,应该能接受各种变化,并且评价关键的相似性。 - DeepCache - 把视频帧分割成细致的区域 - 寻找相似区域与缓存帧之间的相似性 - FoggyCache 1. 通用表示将异构的原始输入数据嵌入到特征向量中。 2. A-LSH 给这些特征向量加索引,方便下一步操作。 3. kNN 移除异常值,决定哪些特征向量能复用。 - Mainstream - 不是复用**结果**,而是复用**过程** - 适应性地编排DNN的共享枝干(一些特化的DL模型中的共同部分) - 尽管**高度特化的DL模型**准确率更高、共享成分更低 - 但是**低度特化的DL模型**的准确率并不比高度特化的差多少。 - 所以,大部分DL模型可以一个低的准确度损失,来共享。 # 用于DL的边缘计算 边缘DL的部署,需要: 1. 网络层架构 2. 边缘软件硬件的设计、适配、优化 特别的: 1. 定制的边缘硬件 - 相应地优化软件框架、库 2. 边缘计算架构 - 能够卸载DL计算 3. 好设计的计算框架 - 能够更好地维持边缘上运行的DL服务 4. 评估边缘DL表现的好平台 - 能帮助未来改进 ## 用于DL的边缘硬件 ### 移动设备的CPU和GPU - 轻量边缘设备 - 能直接运行DL应用程序 - 包括: - 智能手机 - 可穿戴设备 - 监控摄像头 - 低电量IoT边缘设备 - 承担轻量DL设备的计算任务 - 避免与云通信 - 面临问题: - 计算资源有限 - 内存占用 - 电量消耗 突破低电量IoT设备瓶颈的方法: - CMSIS-NN - 基于ARM Cortex-M 微控制器 - 是一组高效的NN内核 - 能够: - 最小化NN留在ARM处理器核心上的内存占用 - 让DL模型适合IoT设备 - 达到普通表现和能耗 - DeepMon - 把CNN层用的矩阵给分解掉 - 这样手机GPU就能加速高维矩阵操作(尤其是乘法)了 - Mentee network - 用来评估DL训练 - 评估DL模型的大小 ### 基于FPGA的方案 1. GPU对电量和成本的要求高 2. 边缘节点要能同时计算多个请求,轻量的CPU和GPU做不到 - 基于FPGA的边缘设备 - 能加速任意尺寸的卷积和可配置的池化 - 在基于RNN的语音识别中,比最新的CPU和GPU推理得更快,更省电 - FPGA的缺点 - 给FPGA开发高效DL算法,对大部分程序员都不熟悉 - 尽管Xilinx SDSoc可以降低很多难度 - 目前仍需要很多工作,把GPU用的最新的DL模型翻译给FPGA平台。 ### 方案的比较 - 资源开销 - FPGA最好 - FPGA可以通过定制化的设计,来优化 - DL训练 - GPU最好 - GPU的浮点运算能力更好 - DL推理 - FPGA最好 - 可以为具体DL模型定制FPGA - 接口可伸缩性 - FPGA最好 - FPGA在实现接口上更自由 - 空间占用 - CPU/FPGA最好 - 低功耗的FPGA顺带更小的空间占用 - 兼容性 - CPU/GPU最好 - CPU和GPU有更稳定的架构 - 开发工作 - CPU/GPU更好 - 实际开发中的工具链和软件库很方便 - 能效 - FPGA更好 - 可以用定制化的设计来优化 - 并发支持 - FPGA更好 - FPGA适合流处理 - 时钟?(Timing latency) - FPGA更好 - FPGA的时钟可以比GPU的快一个数量级 ## 通信和计算模式 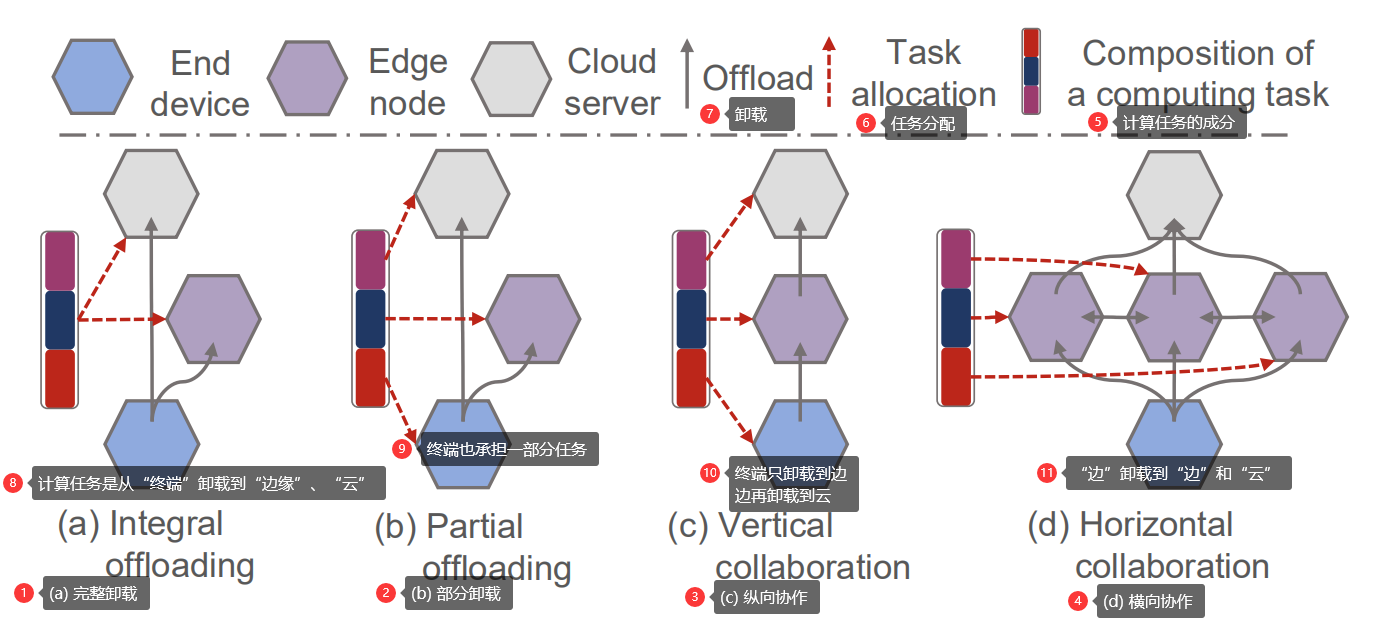 ### 完整卸载 - 完整卸载 - 把DL任务分解 - 有资源优化的问题 - 可能增加计算成本和调度延迟 - 要协调: - 推理准确率 - 推理时延 - DL模型大小 - 电量 - 网络状况 - 要有多个虚拟机或容器 - 分开部署不同大小的DL模型 ### 部分卸载 - 部分卸载 - 例:MAUI - 适应性分解一般的电脑程序,通过优化任务分配策略, - 可以在程序运行的时候分解,取代部署程序时的手动分解 - 例:DeepWear - 把DL模型抽象成有向无环图(DAG) - 点=DL的层 - 边=数据流 - 决定卸载方式: - 保留计算集中的点(DL层) - 组合重复的DAG子图 - 能把复杂DAG变成简单、线性的DAG,来用线性复杂度的方案优化卸载 - 例:IONN - 背景:上传一部分DL模型到边缘节点的过程,可能会延迟整个DL计算。 - 将一个DL模型切成多个部分,依次上传到边缘节点 - 边缘节点收到后,再组装。 - 可以再上传完毕整个模型之前,就执行DL计算。 - 一方面可以先上传表现与开销都好的部分 - 另一方面,不能带来表现提升的,就不必上传了 ### 纵向协作 解决的是:同一时间的查询太多的时候,单个边缘节点不够用的问题。 - 边缘节点: - 卸载DL任务的时候,进行预处理、初步的学习 - 把中间结果(边缘的输出)传给云,做进一步的DL计算 中间结果要远小于原始输入 - 纵向卸载的优势: - 当边缘架构无法独自支撑大量DL查询的时候,云架构可以分担部分计算任务,让边缘能维持服务。 - 原始数据必须在传给云之前进行预处理。如果能极大减少尺寸,能减轻主干网的压力 ### 横向协作 训练好的DNN模型或整个DL任务,可以被分割并部署在多个终端节点或边缘节点。 - MoDNN - 通过WLAN,在本地分布式移动计算系统上执行DL。 - DNN的每层被分成片,来增加平行性,以及减少内存占用。 - Fused Tile Partitioning(FTP) - 把每个CNN层独立可分布的任务 ## 边缘DL框架 - 需求: - 匹配边缘平台和DL模型 - 基于性能和电量,充分利用底层硬件 - 自动安排和指挥DL服务 ### 在哪部署 首先要决定在“边缘计算网络”中的哪里 部署DL服务。 - RAN控制器:部署在边缘节点,以收集数据和运行DL服务 - 网络控制器:部署在云,安排RAN控制器的操作 ### 开发环境与部署环境的桥接 部署环境用的是边缘上的DL框架,而开发DL模型用的是PyTorch、TensorFlow等。 - 部署工具+运算符库(operator library) - ALOHA工具流 - 自动化模型设计 - 根据目标任务、约束条件、目标架构 生成最优的模型配置 - 优化模型配置 - 分割DL模型,生成“考虑架构”的“不同推理任务 → 可用资源”映射信息 - 自动化模型移植 - 目标架构将映射信息翻译成调用计算和通信的语句 ### 协调DL模型部署到边缘 - OpenEI - 将每个DL算法成4元素的元组,来衡量边缘DL在目标硬件平台上的能力 - Accuracy - Latency - Energy - Memory Footprint - 基于以上元组,OpenEI可以按EdgeDL功能,为特定平台选模型 - Zoo - 提供简明的“特定领域语言”(Domain-specific Language,DSL) - 让DL服务的组合,简单又类型安全 - ECO - 用基于图的铺盖网络 1. 建模和跟踪管道和依赖关系 2. 把它们映射到分布式分析引擎 - 用这种方法来管理开销和性能 ## 边缘DL的表现评价 ### 评价指标 - latency - memory footprint - energy ### 对手机DL的测评 - AI Benchmark - 对不同手机评估DL计算能力 - 结果显示没有一个DL库或硬件平台能完全胜过其他的 - 说明仍有机会对边缘硬件、边缘软件、DL库进一步优化 ### 对边缘DL的测评 - 没有对边缘DL的测评平台。 - 阻碍了对边缘DL架构的研究 - 不但要考虑边缘的计算架构,还有结合终端设备和云 - openLEON 和 CAVBench - 针对汽车场景 ### 测评平台要考虑什么 - 模拟DL服务的控制面板 - 持续的无线连接和网络模型 - 模拟服务请求 - 边缘计算平台 - 云架构 # 关于边缘通信和DL计算模式的细节 ## 完整卸载 ### DeepDecision **DL模型:**YOLO **端:**Samsung Galaxy S7 **边:**2.7GHz四核CPU, GTX 970 and 8GB RAM **云:**无 **网络:**Simulated WLAN & LAN **依赖:**TensorFlow, Darknet **任务:**综合考虑模型准确率、视频质量、电量约束、网络数据使用、网络情况,来优化卸载策略 **表现:**实现了15FPS的视频相对baseline的准确率的提升 ### MASM **DL模型:**无 **端:**Simulated devices **边:**Cloudlet **云:**无 **网络:**无 **依赖:**无 **任务:**优化任务分配 与 Cloudlet中的虚拟机的计算能力 **表现:**无 ### EdgeEye **DL模型:**DetectNet, FaceNet **端:**摄像头 **边:**i7-6700, GTX 1060, 24GB RAM **云:**无 **网络:**WIFI **依赖:**TensorRT, ParaDrop, Kurento **任务:**将“实时视频分析任务”卸载到边缘,用EdgeEye API,而不是用DL框架的API,来提供更好的推理表现 **表现:**无 ## 部分卸载 ### DeepWear **DL模型:**MobileNet, GoogleNet, DeepSense, etc. **端:**运行Android Wear OS的商品智能手表 **边:**商品安卓手机 **云:**无 **网络:**蓝牙 **依赖:**TensorFlow **任务:**提供有上下文的卸载,战略性的模型分割、充分利用边缘能力的流水线 **表现:**带来5.08倍和23.0倍的执行提速,和53.5%和85.5%能源节省,各自相比于“只穿戴”、“只手持”的策略来说。 ### IONN **DL模型:**AlexNet **端:**Embedded board Odroid XU4 **边:**3.6GHz四核CPU, GTX 1080Ti and 32GB RAM **云:**未注明 **网络:**WLAN **依赖:**Caffe **任务:**分割DNN层,增量上传分割的DNN层,以允许“端边”或“端云”协作执行,改进彼此的查询性能和能源消耗 **表现:**维持与整体上传相同的上传时延,同时大幅改进查询执行时间 ## 纵向协作 ### When deep learning meets edge computing **DL模型:**CNN, LSTM **端:**Google Nexus 9 **边:**四核CPU, 16GB RAM **云:**3台 i7-6850K, GTX1080Ti x2 **网络:**WLAN&LAN **依赖:**Apache, Spark, TensorFlow **任务:**在边缘进行数据预处理和初步学习,以降低网络流量,加速云上的计算 **表现:**在降低执行时间和数据传输的情况下,达到90%的准确率 ### Neurosurgeon **DL模型:**AlexNet, VGG, Deepface, MNIST, Kaldi, SENNA **端:**Jetson TK1 mobile platform **边:** Intel Xeon E5×2, NVIDIA Tesla K40 and 256GB RAM **云:**未注明 **网络:**WIFI, LTE & 3G **依赖:**Caffe **任务:**适配各种DNN架构、硬件平台、无线连接、服务器负载级别,选择分割点,已达到最好的延迟和最好的能源消耗 **表现:**端到端延迟平均有3.1倍的改进,最高有40.7倍改进;减少能源消耗平均59.5%,最高94.7%;提高数据中心吞吐量平均1.5倍,最高6.7倍。 ### Distributed Deep Neural Networks over the Cloud, the Edge and ENd Devices **DL模型:**BranchyNet **端:**无 **边:**无 **云:**无 **网络:**无 **依赖:**无 **任务:**在低延迟分类中,最小化通信和设备资源使用 **表现:**将通信成本降低到20倍以上,同时达到95%的总体准确度 ### Distributed and Efficient Object Detection in Edge Computing: Challenges and Solutions **DL模型:**Faster R-CNN **端:**Xiaomi 6 **边:**i7 6700, GTX980Ti , 32GB RAM **云:**E5-2683 V3, GTX TitanXp×4, 128GB RAM **网络:**WLAN & LAN **依赖:**无 **任务:**通过端边云之间的无线通信,实现高效的目标检测 **表现:**在图像压缩率60%、显著提高图像传输效率的情况下,只损失2.5%检测准确率 ### VideoEdge **DL模型:**AlexNet, DeepFace, VGG16 **端:** 10 Azure nodes emulating cameras **边:** 2 Azure nodes **云:** 12 Azure nodes **网络:**仿真分层网络 **依赖:**无 **任务:**介绍主要需求,确定资源数 与 准确率 之间的最佳权衡 **表现:**与VideoStorm相比提高了5.4倍准确率,而且与最佳情况相比,只损失6%准确率。 ## 横向协作 ### MoDNN **DL模型:**VGG-16 **端:**Multiple LG Nexus 5 **边:**无 **云:**无 **网络:**WLAN **依赖:**MXNet **任务:**切分已经训练好的DNN模型,分别放在若干移动设备上,来减轻设备的计算成本和内存占用,以加速DNN计算 **表现:**工作节点数量从2增加到4,MoDNN可以将DNN计算加速2.17到4.28倍 ### Fused-layer CNN accelerators **DL模型:**VGGNet-E, AlexNet **端:**Xilinx Virtex-7 FPGA 模拟多终端设备 **边:**无 **云:**无 **网络:**芯片上模拟 **依赖:**Torch, Vivado HLS **任务:**合并多个CNN层,启用中间数据缓存以节省数据传输带宽 **表现:**将总体数据传输降低了95%,每张图像从77MB降到3.6MB ### DeepThings **DL模型:**YOLOv2 **端:**限制性能的树莓派3 B型 **边:**树莓派3 B型 当做网关 **云:**无 **网络:**WLAN **依赖:**Darknet **任务:**采用可伸缩的熔合块分区,来切分CNN层,在暴露并行性的同时最小化内存占用,并采用新颖的工作调度流程来减少总体执行延迟 **表现:**降低了68%的内存占用,并没有牺牲准确率,吞吐量提高了1.7到2.2倍,加速CNN推理1.7到3.5倍 ### DeepCham **DL模型:**AlexNet **端:**多个 LG G2 **边:**WIFI路由器连接的Linux服务器 **云:**无 **网络:**WLAN & LAN **依赖:**Android Caffe, OpenCV, EdgeBoxes **任务:**协调参与的移动用户 共同训练一个域感知适应模型,来提高目标识别的准确率 **表现:**与仅仅使用DL模型相比,目标识别准确率提高了150% ### LAVEA **DL模型:**OpenALPR **端:**树莓派2和树莓派3 **边:**4核CPU, 4GB RAM **云:**无 **网络:**WLAN & LAN **依赖:**Docker, Redis **任务:**设计各种边际协作的任务摆放方案,最小化服务回应时间 **表现:**相比于本地运行,有1.3到4倍的加速;相比于 客户端-云,有1.2到1.7倍的加速 # 边缘中的DL训练 - 现在是“云训练”,或“云边训练” - 训练数据在边缘预处理,上传到云 - 不适合所有的DL服务 - 特别是当模型需要位置、要持续训练时 - 要消耗大量通信资源 - 终端设备和边缘节点是分布(数量很多) - 要连续往云上传数据 - 例如监控摄像头 - 有隐私问题 - "端边云” - 在边上训练 - 将边缘视为训练的核心 - 需要大量资源来消化分布式数据 与 交换更新 - 联邦学习(FL)用来解决这个问题 ## 边缘的分布式训练 - 论文:Pushing Analytics to the Edge - 首个在边缘进行分布式训练的研究 - 去中心化的SGD(随机梯度下降) - 用于解决大型线性回归问题 - 是为大型图像应用设计的 - 无法泛化到其他DL训练 - 因为训练大型DL模型的通信成本极高 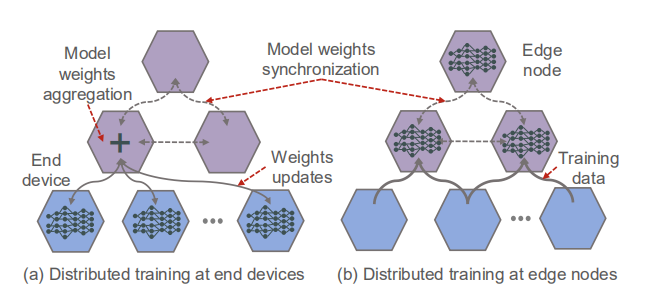 ### 在终端设备训练 - 终端设备用本地数据训练 - 在边缘节点合并权重,来升级模型 ### 在边缘节点训练 - 边缘节点训练本地模型 - 提炼组合成全局模型 - 能避免上传大量原始数据到云 - 但避免不了边缘节点之间互换梯度信息 - 边缘节点可能承受更高延迟、更低传输率、不稳定的连接 - 会阻碍不同节点之间梯度交换 ### 关于梯度交换 - 梯度交换 - 大部分梯度交换是冗余的 - 梯度可以压缩,来减少通信成本,维持训练准确率 - DGC 1. 规定只有重要的(大于阈值)梯度才会被交换 - 阈值是启发式给的 - 为了避免信息丢失,小于阈值的梯度会被累加,直到超过阈值(延迟传输) - 阈值传输之前会被压缩,以降低通信成本 2. 用 动量校正、本地梯度修剪,来避免梯度的稀疏更新对DL训练的影响 - 动量校正:把**稀疏更新**变成近似相等的**稠密更新** - 本地梯度修剪:在新梯度与旧梯度相加之前,对梯度进行修剪,来避免梯度爆炸的问题 3. 对延迟传输的梯度不进行动量校正 - 由于低于阈值的梯度会延迟传输,确实会拖慢汇集 4. 开始训练的时候,用 不大的学习率,和稀疏的梯度 ### 关于降低“同步梯度与参数”的通信成本 关于降低分布式训练的“同步梯度与参数”的通信成本,用两种方法可以结合使用: - 只传输重要的梯度(利用稀疏梯度) - 用隐藏层,记录一个梯度坐标参与梯度同步的时间 - 梯度坐标的隐藏权重越大,这个梯度就越重要,更可能被选进下一轮训练 - 小梯度不能丢,应该累加 - 过时的梯度,应该折旧 ## 边缘的联邦学习(FL) 在联邦学习(FL)中,移动设备是被当成用于本地训练的客户。 在边缘计算中,移动设备可以有更多用途。 终端设备、边缘节点、云服务器,就相当于FL的不同客户,承担不同的计算任务,来组合全局DL模型。 - FL不断地找随机边缘设备来: - 下载全局DL模型,从一个“聚合服务器” - 用自己的数据,训练下载下来的模型 - 只上传模型的“更新的部分”给“聚合服务器”,来取平均 ### 联邦学习能解决边缘计算的关键问题dz: #### 非独立同分布的训练数据 每个设备的训练数据都是设备自己感应、收集的。 任一个训练样本都不能代表全局。 可以参考FL的*FederatedAveraging* #### 有限的交流 设备可能处在离线 或者信号不好的环境。 在资源足够的设备上训练模型,可以减少“训练全局模型”的通信轮数。 FL的每一轮训练,只需要一部分设备上传更新。 成功解决有的设备意外离线的问题。 #### 不平衡的贡献 可以用*FederatedAveraging* #### 隐私和安全 需要上传的只有模型的更新部分。 安全聚合和差异隐私 有助于避免泄露本地更新中包含的隐私敏感数据。 ## FL的通信效率 假设DL模型大小足够大,从边缘设备到中心服务器的上传语言(如模型权重)也可能消耗不可忽略的通信资源。 ### 降低通信量 - 降低通信量的方案: - FL客户按周期(不是连续)与中央服务器通信 - 结构化更新 - 将模型更新限制为具有预先指定的结构 - 低秩矩阵 - 稀疏矩阵 - 草图更新 - 保留完整的模型更新 - 上传之前,压缩传输量 - 子采样 - 概率量化 - 结构化随机旋转 ### 区分上下行 - 下行(服务器→设备) - 将全局DL模型的权重压缩成向量,然后采用二次采样和量化 - 是有损压缩 - 无法通过“取平均”来减轻损失 - 可以先用*Kashin's representation*的基变换,来减少压缩带来的错误 - 上行(设备→服务器) - 由于设备不训练全局模型,而是训练较小的子模型(剪枝出来的模型),所以比全局模型更轻量,上传量减少。 ### 区分边缘设备 边缘设备的: - 计算资源是异构的、受限的。 - 训练数据是分布不均匀的 - 功能强大的边缘设备: - 持续训练 - 定时聚合 - 一般的边缘设备: - 在给定资源预算的情况下,基于非IID数据的分布式学习收敛边界,优化聚合频率。 - Astraea - 基于中介器多客户端重新调度策略 - 数据增强,以缓解数据的分布不均匀 - 一套数据,变出多种**数据分布** - 将客户端分配给中介(贪婪策略) - 将未分配过的**数据分布**,发给合适的客户端 - 当中介到达最大客户端限制时,中央服务器新建一个中介并重复该过程,直到所有客户端都被分配了训练任务 - ?节省了92%的通信流量 ### 利用无线信道的干扰 - 无线多址接入信道(wireless multiple-access channel)有叠加的特性(一般被视为干扰) - 多个边缘设备并发传输,每条传输占一个信道 - 聚合服务器可以同时听全部信道,由信道系数加权。不需要其他的聚合操作。 ## 资源优化的FL 解决的是:如何不让算得慢的设备 拖慢全局模型聚合 的问题。 ### 屏蔽神经元 - ELFISH - 分析训练模型的时间成本、内存使用、计算工作量 - 确定每一层需要屏蔽哪些神经元,以保证训练模型的计算消耗满足特定的资源约束 - 在每个训练周期中动态地寻找不同的神经元集合,并在随后的聚合阶段进行恢复和更新 ### 总时钟 总时钟时间 = 计算时间 + 通信时间 计算时间=f(客户机的计算能力,本地数据尺寸) 通信时间=g(客户机的信道增益,传输功率、本地数据大小) ### 公平目标 - q-FFL - 评估精度分布中的方差 - 最小化这个方差,就达到了最公平的效果。 - 用于节点资源优化 ## 安全增强的FL 尽管FL都是边缘设备本地处理本地的数据,但服务器不能完全相信边缘设备: - 设备的异常行为会伪造或毒化训练数据,造成无价值的模型更新,危害全局模型。 - 不可预测的网络状况和计算能力 也会影响安全性 反过来说,聚合服务器的故障,可能会导致全局模型更新不准确,从而导致所有本地模型失真。 ### 异常值/毒化值 - *robust federated optimization* - 定义了平均修剪操作 - 不光能过滤掉毒化设备的值 - 也能过滤普通设备的异常值 ### 意外掉线 - 安全聚合(Secure Aggregation)协议 - 达到“容忍多达三分之一的设备无法及时处理本地训练或上传更新”的鲁棒性 ### 聚合服务器故障 - 区块链 + FL = BlockFL - 每个边缘节点都维持全局模型 - 而不是只有聚合服务器有全局模型 - 确保在更新全局模型时的设备故障,不会影响其他节点的本地更新 - 激励机制,奖励参与FL的边缘节点 # 优化边缘的深度学习 - DNNs可以处理网络中的用户信息和数据度量,感知无线环境和边缘节点的状态 - DRL可用于学习长期最优资源管理和任务调度策略,从而实现边缘的智能化管理,即智能化边缘 ## 自适应边缘缓存 两个挑战: 1. 边缘覆盖范围内,内容的流行度分布 难以估计 - 因为可能会随时间变化 2. 大量异构设备、层次结构、复杂的网络特征 只有在知道内容的流行程度的情况下,才能得出最佳的边缘缓存策略。  ### DNN的用例 #### 对大众的流行程度 - 传统缓存方法 - 计算复杂度很高 - 需要大量的在线迭代 - 确定: - 用户和内容的特征 - 缓存内容的放置和交付策略 - 新方法: - 用户和内容的特征 - 用户原始数据 →DL→ [用户特征 , 受欢迎程度] (流行矩阵) - 流行矩阵 →基于特征的协作过滤→ 估计核心网络的流行内容 - 缓存内容的放置和交付策略 - 训练DNN来优化边缘缓存策略 - √ 离线训练 - × 在线大量计算迭代 - DNN的组成: - 一个编码器(用于数据正则化) - 一个隐藏层 - 训练方法: - 最优或启发式算法 - 训练结果用于本地缓存部署,避免线上优化迭代 - 训练MLP - 输入:内容流行度,最后一次内容放置概率 - 输出:缓存刷新策略 - 新旧方法的比较 - DNN可以把优化算法的复杂度转移到训练DNN上,从而突破实际应用的局限性 - DL用于学习“输入-结果”的关系,只在存在这种最优关系的时候才能用 - DNN方法不如固定的优化算法,且无法自适应。 - 然而热点内容是会变化的,所以“输入-结果”的最有关系持续不 #### 个性化的流行程度 例如一辆自动驾驶汽车,可以根据车主的性别、年龄,来判断车主的喜好,来缓存一些东西。 - 云端: - 用MLP 预测请求内容的流行程度 - 把输出发送给边缘节点 - 汽车: - 用CNN 预测车主的年龄和性别 - 再用k均值、二进制分类,决定将边缘节点的哪些内容下载到车上。 - 用RNN 预测用户轨迹 - 用户感兴趣的所有内容会被预缓存到预测位置的边缘节点上。 ### DRL的用例 DNN无法解决整个优化问题(无法自适应),只能是整个问题的一部分。 DRL可以探索“用户-网络”的上下文,可以采用自适应的策略,来最大化长期的缓存性能,作为整个优化方法的主体。 - 传统RL算法 的限制: - 手工测绘特征 - 难以处理高维观测数据和动作 - DRL: - 例如:Q-learning,Multi-Armed Bandit(MAB)learning - 可以对原始观测数据用DNNs来学习关键特征 - DDPG - 用于训练DRL代理 - 让缓存的长期命中率最大化 - 考虑单个BS(Base Station 基站)的场景 - DRL代理: - ?决定是缓存请求的内容,还是替换缓存的内容 - 奖励: - 缓存的命中率 - Wolpertinger架构 - 用于应对 大的行动空间 - 先给DRL代理 设置主行动集 - 然后用kNN将实际行动映射到主行动集中的一个 - 可以在不丢失最佳缓存策略的情况下缩小操作空间。 ## 优化边缘任务卸载 - 需要辨识: 1. 哪些边缘节点应该接收任务 2. 边缘设备应该卸载多大比例的任务 3. 对这些任务应该分配多少资源 - 要同时考虑: 1. 时变无线环境 - 例如变化的信道质量 2. 任务卸载请求  ### DNN的用例 计算卸载问题可以视为:多标签分类问题 - 标记:离线,穷举搜索,找到最优的卸载方案 - 输入:边缘计算网络的复合状态 - 输出:卸载决策 #### 关于区块链的卸载策略 - 关于区块链的卸载策略 - 在边缘设备上挖矿,所造成的计算/能源的资源消耗,可能会限制区块链在边缘计算网络中的实际应用 - 挖矿任务 从边缘设备 卸载到边缘节点,可能会造成不公平的资源分配。 - 所以,所有可用资源都要以“拍卖”的形式分配,来最大化“边缘计算服务提供商”(Edge Computing Service Provider, ECSP)的收入。 - 基于最优拍卖的解析解,可以构造MLP,并用矿工(边缘设备)的估值来训练MLP,以使ECSP的预期收入最大化。 ### DRL的用例 计算卸载:↑提高处理效率 ↓降低可靠性 (无线环境的潜在的低质量) - 《DeepLearning Empowered Task Offloading for Mobile Edge Computing inUrban Informatics》 - 量化了 各种通信模式 对任务卸载性能的影响 - 提出相应的DQL(Deep Q-Learning),用来在线选择: - 最优目标边缘节点 - 传输模式 修改DDQL(Double Deep Q-Learning)的DRL代理,可以为终端设备分配边缘计算和带宽资源。 保证卸载可靠性的关键:传输数据的编码率 - 《Deep Reinforcement Learningbased Resource Allocation in Low Latency Edge Computing Net-works》 - 研究了编码块长度对资源分配的影响 - 制定了资源分配的MDP(Markov Decision Process),并用DQL求解 - 《Adouble deep q-learning model for energy-efficient edge scheduling》 - 用DDQL,决定最佳“动态电压频率缩放”(Dynamic Voltage and Frequency Scaling, DVFS)算法 - 可以比DQL的更节省能源,达到更高的训练效率 - Energy Harvesting (EH)物联网边缘环境 - IoT边缘设备可以从环境射频信号中 收获能量 - 收获能量,会让卸载问题变得复杂 - CNN可以用来压缩状态空间 - 基于策略梯度的DRL能执行更细粒度的控制 随意让DRL代理 接管整个计算卸载过程,会导致巨大的计算复杂性。 只用DNN来做部分决定,可以大幅降低复杂性。 最好是分成两个子问题:卸载决策,资源分配 ## 管理和维持 Edge DL 计划是部署在蜂窝网络的基站上。 所以,边缘管理,要从多个方面优化——包括通信方面。 许多工作都集中在 将DL应用于无线通信。 然而,管理和维护需要考虑更多方面。 ### 边缘通信 #### 移动性 基于DL的方法,能够帮助设备与边缘节点之间的链接 平滑过渡。 - DNN → 最优的设备关联策略 - 在中央服务器,建立数字孪生网络,来离线训练DNN - MPL → 预测给定位置和时间的可用节点 - 最大限度地减少边缘节点间切换的中断 - 用LSTM的双层RNN → 评价端边的互动成本 - 成本(服务请求的延迟) - DQL → 控制通信模式,控制边缘设备的开关 - 物联网的多种通信模式: - Cloud-Radio Access Networks (C-RAN) - Device-to-Device (D2D) - Fog radio Access Point (FAP) - TL(迁移学习) → 与DQL集成,减少DQL训练过程所需的交互 #### 安全性 1. 主动检测未知攻击 - 用DL技术,提取窃听和拥塞攻击的特征 2. 决定安全防护策略 - 安全防护需要额外电量和计算 - 每个边缘设备应该优化防护策略,例如选择发射功率、信道、时间,而不突破资源上限 - 由于攻击模型和动态边缘计算模型难以估计,使这个优化具有挑战性 - DRL → 从边缘设备到边缘节点的安全卸载 - 对付拥塞攻击 - 保护用户位置隐私和使用模式隐私 - 边缘设备: - 观察边缘节点状态和攻击特性 - 决定防御等级 和安全协议的关键参数 - DQL → 应对各种类型的攻击 - 将奖励设置为:抗干扰通信效率 - 例如:信号的信噪比、接收消息的误码率和保护开销 #### 关节边缘优化 边缘计算可以应对快速增加的智能设备,能有处理“计算密集”和“数据消耗”的应用。 这导致未来网络的行为会非常复杂。 为了综合资源优化、管理复杂网络,就有:软件定义网络(SDN),物联网(IoTs),车联网(IoVs) - 软件定义网络(SDN) - 把控制平面与数据平面分开 - 从而允许以全局视图在整个网络上进行操作 - 是集中式方法 - 用于边缘计算网络,具有挑战性 - 有支持SDN的边缘计算网络,用于智慧城市 - DQL部署在其控制平面,以协调网络、缓存、计算资源 - 物联网(IoT) - 边缘计算为物联网系统提供“计算集中”和“延时敏感”的服务 - 这对高效管理、存储的同步、计算、通信资源带来挑战 - 基于策略梯度的DRL + Actor-Critic (AC)框架 - 用于最小化平均端到端时延 - 分配边缘节点 - 决定是否存储请求内容 - 选择执行计算任务的边缘节点 - 分配计算资源 - 车联网(IoV) - 是物联网的具体案例,关注的是联网的汽车 - 在缓存和计算方面,DDQL比DQL有更好的鲁棒性,能用于整合可用资源。 - 要关注 汽车的移动性 - 建模: 汽车的移动 → 离散随机跳变 - 分时段:时间轴分为多个Epoch,每个Epoch包含一些时隙 - DQL(小时间尺度,时隙) → 及时反馈 - DQL(大时间尺度,epoch) # 用于优化边缘的DL-应用场景 ## 自适应边缘缓存 ### DeepCachNet: A Proactive Caching Framework Based on Deep Learning in Cellular Networks **模型:**SDAE **规模:**60用户 / 6个基站 **DNN输入(DRL状态):**用户特征,内容特征 **DNN输出(DRL行动):**基于特征的内容流行度矩阵 **损失函数(DRL奖励):**输入特征和之后重构的归一化差异 **表现:**QoE(体验质量):提升30%,回程卸载:6.2% ### Learn to Cache: Machine Learning for Network Edge Caching in the Big Data Era **模型:**FCNN **规模:**每个单元100-200用户设备 / 7个基站 **DNN输入(DRL状态):**信道状况,文件请求 **DNN输出(DRL行动):**缓存策略 **损失函数(DRL奖励):**预测的策略与最佳策略的归一化差异 **表现:**预测准确率:高达92%,能源消耗:与最佳相差8% ### Deep learning-based edge caching for multi-cluster heterogeneous networks **模型:**FCNN **规模:**密度25-30的用户设备 / 多层基站 **DNN输入(DRL状态):**当前内容流行度,上一个内容放置的可能性 **DNN输出(DRL行动):**内容放置的可能性 **损失函数(DRL奖励):**模型输出与最优CVX解之间误差的平均值 **表现:**预测准确率:轻微退化到最佳状态 ### Deep Learning Based Caching for Self-Driving Car in Multi-access Edge Computing **模型:**FCNN,CNN **规模:**汽车 / 6个带有MEC(移动边缘计算)服务器的RSU(路侧单元) **DNN输入(DRL状态):**面部图像(CNN),内容特征(FCNN) **DNN输出(DRL行动):**预测性别和年龄(CNN),内容请求的可能性(FCNN) **损失函数(DRL奖励):**无(CNN),交叉熵误差(FCNN) **表现:**缓存准确率:高达98.04% ### A smart caching mechanism for mobile multimedia in information centric networking with edge computing **模型:**RNN **规模:**20个用户设备 / 10个服务器 **DNN输入(DRL状态):**用户历史轨迹 **DNN输出(DRL行动):**用户位置预测 **损失函数(DRL奖励):**交叉熵误差 **表现:**缓存准确率:高达75% ### A deep reinforcement learning-based framework for content caching **模型:**DDPG **规模:**多个用户设备 / 单个基站 **DNN输入(DRL状态):**缓存内容的特征,当前请求 **DNN输出(DRL行动):**内容的替换 **损失函数(DRL奖励):**缓存命中率 **表现:**缓存命中率:大约50% ## 优化边缘任务卸载 ### Optimal Auctionfor Edge Computing Resource Management in Mobile BlockchainNetworks: A Deep Learning Approach **模型:**FCNN **规模:**20个矿工 / 单个边缘节点 **DNN输入(DRL状态):**矿工的投标估价信息 **DNN输出(DRL行动):**分配概率,有条件的付款 **损失函数(DRL奖励):**服务提供商的预期负收入 **表现:**收入增加 ### 【257】 **模型:**DDQL **规模:**单个用户设备 **DNN输入(DRL状态):**系统使用状况,动态松弛状态 **DNN输出(DRL行动):**DVFS算法的选择 **损失函数(DRL奖励):**平均能源消耗 **表现:**能源节省:2%~4% ### 【253】 **模型:**DQL **规模:**多个用户设备 / 单个eNodeB **DNN输入(DRL状态):**整个系统的成本,MEC服务器的可用能力 **DNN输出(DRL行动):**卸载策略,资源分配 **损失函数(DRL奖励):**与总成本负相关 **表现:**系统成本降低 ### 【255】 **模型:**DDPG **规模:**多个用户设备 / 单个带有MEC服务器的基站 **DNN输入(DRL状态):**信道向量,任务序列长度 **DNN输出(DRL行动):**卸载决策,功率分配 **损失函数(DRL奖励):**功耗和任务队列长度的负加权和 **表现:**计算成本降低 ### 【254】 **模型:**DQL **规模:**单个用户设备 / 多个MEC服务器 **DNN输入(DRL状态):**前一个无线带宽,预测的收获能源,当前电量 **DNN输出(DRL行动):**MEC服务器选择,卸载率 **损失函数(DRL奖励):**总体数据共享增益、任务丢失、能源消耗、延迟 **表现:**节省能源,改进延迟 ### 【251】 **模型:**DDQL **规模:**单个用户设备 / 6个带有MEC服务器的基站 **DNN输入(DRL状态):**信道增益状态,用户设备-基站 的关联状态,能源队列长度,任务队列长度 **DNN输出(DRL行动):**卸载决策,能源单位分配 **损失函数(DRL奖励):**任务执行延迟、任务丢弃次数、任务排队延迟、任务失败惩罚、服务付费 **表现:**卸载效果提升 ### 【258】 **模型:**DROO **规模:**多个用户设备 / 单个MEC服务器 **DNN输入(DRL状态):**信道增益状态 **DNN输出(DRL行动):**卸载行为 **损失函数(DRL奖励):**计算速率 **表现:**在30个用户设备的网络里,执行时间小于0.1秒 ## 管理和维持 ### 通信 #### 【259】 **模型:**RNN & LSTM **规模:**53辆车 / 20个雾服务器 **DNN输入(DRL状态):**协调车、雾节点的互动,时间,服务成本 **DNN输出(DRL行动):**成本预测 **损失函数(DRL奖励):**平均绝对误差 **表现:**预测准确率:99.2% #### 【260】 **模型:**DQL **规模:**4个用户设备 / 多个RRH(Remote Radio Head) **DNN输入(DRL状态):**当前处理器的开关状态,当前与用户设备的通信模式,缓存状态 **DNN输出(DRL行动):**处理器状态控制,通信模式的选择 **损失函数(DRL奖励):**系统能量消耗 **表现:**系统功耗 ### 安全性 #### 【261】 **模型:**DQL **规模:**多个用户设备 / 多个边缘节点 **DNN输入(DRL状态):**干扰功率,信道带宽,电池电量,用户密度 **DNN输出(DRL行动):**边缘节点和通道的选择,卸载率,传输功率 **损失函数(DRL奖励):**防御成本,保密能力 **表现:**信号的SINR(信噪比)增加 ### 节点优化 #### 【110】 **模型:**Double-Dueling DQL **规模:**多个用户设备 / 5个基站,5个MEC服务器 **DNN输入(DRL状态):**每个基站、MEC服务器的状态、内容缓存 **DNN输出(DRL行动):**基站分配、缓存策略、卸载策略 **损失函数(DRL奖励):**接收的信噪比,计算能力,缓存状态 **表现:**系统效用增加 #### 【262】 **模型:**AC DRL **规模:**每个路由20个用户设备 / 3个雾节点 **DNN输入(DRL状态):**请求、雾节点、任务、内容、信噪比的状态 **DNN输出(DRL行动):**关于雾节点、信道、资源分配、卸载和缓存的决策 **损失函数(DRL奖励):**计算卸载延迟和内容交付延迟 **表现:**平均服务延迟:1.5-4.0秒 #### 【112】 **模型:**DQL **规模:**50辆车 / 10个路侧单元(RSU) **DNN输入(DRL状态):**路侧单元、车和缓存的状态,接触率,接触时间 **DNN输出(DRL行动):**RSU分配、控制,缓存控制 **损失函数(DRL奖励):**通信、存储和计算的成本 **表现:**回程能力缓解,节省资源 # 经验和挑战 ## 更有前景的应用 如果DL和边缘 能够很好的集成,它们就能为创新应用的开发提供巨大的潜力。 - 云架构难以满足延迟要求。 - 边缘计算架构靠近用户,可以利用云来形成一个混合架构 - 智能驾驶 - 涉及:语音识别、图像识别、智能决策 等 - 各种DL应用(例如:碰撞警告)需要边缘计算平台 毫秒级的延迟 - 边缘感知 更有利于分析车辆周围的交通环境,从而提高行车安全性 ## 一般DL模型推理 在边缘设备部署DL时,有必要通过模型优化来加速推理。 ### 不明确的性能指标 普通的DL性能指标反应不了**运行时候**的边缘DL性能。 - 普通DL的性能指标: - top-k 准确率 - 平均准确率 - Edge DL的特殊性: - 网络的不确定性 - 不同的无线信道质量 - 不可预测的并发服务请求 - 边缘DL服务 的关键指标 - 模型准确率 (model accuracy) - 推理延迟 (inference delay) - 资源消耗 (resource consumption) - 服务收入 (service revenue) 应该辨认出关键性能指标,量化分析影响它们的因素,再权衡这些指标。这样能提高边缘DL的部署效率。 ### 推广EEoI (Early Exit of Inference) 当前,EEoI用于DL的分类问题,但没有用于更广泛的DL应用。 此外,想构建**智能边缘**,不光要探索DL,还要对DRL用EEoI。 (因为用DRL对边缘进行实时资源管理,需要严格的相应时间) ### 混合模型修改 模型优化、模型分割、EEoI ,应该同时考虑。 - 通常的“端边云”协作模型: - 模型优化(例如:量化和剪枝) - 通常在端和边 - 云不需要优化 - 云的计算资源充足 - 优化对准确率有风险 - 混合精度模式(hybrid precision scheme) - 边缘:简化的DL模型 - 云:原始DL模型 - 训练和推理的协调 - 对原始DL模型进行 剪枝、量化、引入EEoI,需要重新训练,以使其具有期望的推理性能。 - 一般的模型 - 可以在云中离线训练 - Edge DL的特殊: - 边缘计算的优势在于它的相应速度 - 可能会因为相关的训练而被抵消 - 大量异构设备和动态网络环境 - DL模型的定制要求不是单调的 - 持续训练EdgeDL模型的要求不一定合理,可能会影响模型推理的及时性。要看如何避免副作用。 ### 完全边缘架构 边缘智能 和 智能边缘,需要完整的系统框架。 包括:数据收集,服务部署,任务处理。 #### 数据处理的边缘 - 在边缘自适应采集数据,然后传到云端 - ↑ 减少边缘设备的工作负载 - ↑ 降低潜在的资源开销 - 改进:压缩数据再传 - 减轻网络带宽压力 - 降低传输延迟 - 提供更好的服务质量 大部分现有工作都只关注视觉应用。 然而,异构数据结构,各种基于DL的服务的特征 尚未得到很好的解决。 因此,为各种DL服务开发一个异构的、并行的、协作的边缘数据处理架构,会很有帮助。 #### EdgeDL的微服务 边缘和云服务,正在往松耦合的微服务转变。 执行一个DL计算可能需要一系列软件依赖 → 需要一个隔离方案 - 在边缘部署微服务框架的挑战: 1. 解决DL部署与管理的灵活性 2. 实现微服务的实时迁移,减少迁移次数和由于用户移动导致的服务不可用。 3. 在云和分布式边缘设施之间协调资源,以实现更好的性能 #### 完整可靠的DL卸载机制 重型DL计算从终端设备卸载到附近的边缘设备。 - 问题: 1. 应该建立激励机制,刺激边缘节点接管计算任务 2. 要保证安全,避免匿名边缘节点的风险 - 解决方式:参考区块链(不成熟,需要调整) - 所有终端设备和边缘节点必须先将存款存入区块链才能参与 - 终端设备请求边缘节点的帮助进行DL计算,同时向区块链发送一个“需要”交易,并提供奖励 - 一旦边缘节点完成计算,它将结果返回给终端设备,并向区块链发送“完成”交易 - 一段时间后,其他参与的边缘节点也执行卸载任务并验证之前记录的结果 - 最后,第一个记录的边缘节点赢得比赛并获取奖励。 #### 集成“优化边缘的DL” - 将计算密集型DL划分成子任务 - 在线资源编排和参数配置 关键是: - 异构计算资源、通信、缓存资源 的联合计时 - 高维系统参数配置 ### 边缘的训练原则 不同于边缘推理,边缘训练的限制有两个:设备性能,大部分边缘DL框架/库 不支持训练。 #### 数据划分vs模型划分 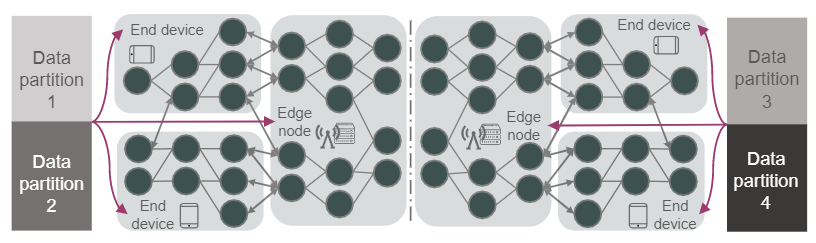 数据划分和模型划分同时做。 挑战:混合 数据并行与模型并行 #### 训练数据来自哪 - 目前大部分边缘训练框架: - 监督学习 - 与用完整数据集的比较 - Edge DL 的特殊性 - 不能假设边缘计算网络的所有数据都被正确标记了 对无监督学习(如DRL)不需要太关注训练数据的生产。 例如:DRL的训练数据(观测状态+与环境交互的奖励)可以自动生成。 对有监督学习,一种可能的方案是:让边缘设备相互学习“标记数据”来构建自己的标记数据。 #### 边缘异步FL 现有的FL方法关注的是同步训练,只能并行处理数百个设备,扩展性可能不好。 1. 不频繁的训练任务。 - 因为边缘设备的算力、电量,不能承担密集训练任务 2. 有限、不确定 的边缘设备之间的通信 - 异步训练机制,可以解决同步训练的瓶颈: 1. 可用边缘设备的选择 2. 同步所选设备的Epoch 3. 个别选择设备掉线了,其余设备要等多久 - 异步训练:在每个周期内聚合尽可能多的客户 - 为客户的下载、更新、上传DL模型 设置截止时间 - 中央服务器可以决定哪些客户端进行本地训练 #### 基于迁移学习(TL)的训练  - 使用未标记的数据,在边缘设备之间传递知识 - 减少训练数据量 - 加快训练过程 - 通过在不同感知模式的边缘设备中 使用跨模迁移(cross-modal transfer) - 减少需要的标记数据 - 加快训练过程 - 用KD(Knowledge Distillation,知识蒸馏) - 用训练好的大型DL模型(teacher)来训练轻量的DL模型(student) - student模型收敛更快 - 能提高student模型的准确性 - 有助于提高student模型的泛化能力 ### 部署和改进智能边缘 - 已有的尝试: - 优化和调度资源 - 潜在的领域: - 在线内容流 - 路由和流量控制  - 找到DL能用的领域不是最重要的 - DL方案不完全依赖于对网络和设备的精确建模 - 要看用DL有没有副作用 - 传训练数据 带来的额外的带宽开销 - DL推理的延迟 - “优化边缘的DL”的部署,有实际问题 - 考虑到DL和DRL的资源开销和对边缘计算网络的实时管理要求,DL和DRL应该部署在哪里? - 当使用DL来决定缓存策略、优化任务卸载的时候,DL的好处会不会被它自身的带宽消耗、处理时间 所抵消 - 如何探索和改进 支持“优化边缘的DL” 的边缘计算架构 - 有没有定制化DL模型的思想,有助于实际部署 - 如何修改训练原则,来增强DL训练的表现,以满足边缘管理的及时性 - 可以探索最先进的DL或DRL - 例如:“多代理DRL” - 终端设备、边缘节点、云 可视为独立代理 - 各自针对自己本地不完美的观测值,来训练自己的策略 - 所有参与的代理,一起优化网络 - 例如:“图神经网络(GNN)” - 交叉了端边云的边缘计算网络 实际是巨大的图 - 包含大量的 潜在的 结构化的信息 - 例如:设备间的带宽 - GNN可以提取图结构的特征,可能是有前途的方法 # 总结 将DL从云 扩展到网络边缘 的关键问题,在于:在**网络、通信、算力、能耗**的多重约束下,如何**设计和开发边缘计算架构**,以实现最好的DL训练与推理表现。 # 边缘智能+区块链论文 - 保障分散不可信环境中的安全交互 - 事务记录 - 对事务记录有效性的分布式共识 - 激励信息的共享与交互(构建经济市场) - 共识机制 - 激励机制 - 智能合约   ## 4种典型共识算法 - PoW(工作量证明) - **如何生成新区块:**挑选节点生成 - **如何挑选节点:**算力 - **故障节点容忍率:**<51% - **缺陷:**消耗计算力资源 - **典型使用场景:**比特币 - PoS(股权证明) - **如何生成新区块:**挑选节点生成 - **如何挑选节点:**代币数量 - **故障节点容忍率:**<51% - **缺陷:**拥有大量代币的节点可能主导区块链 - **典型使用场景:**点点币(Peercoin) - DPoS(股权委托证明) - **如何生成新区块:**挑选节点生成 - **如何挑选节点:**节点投票数&代币数量 - **故障节点容忍率:**<51% - **缺陷:**牺牲了一定的去中心化特性 - **典型使用场景:**比特股(Bitshares) - PBFT(拜占庭容错算法) - **如何生成新区块:**主节点依据各节点发回的相应生成 - **如何挑选节点:**/ - **故障节点容忍率:**<1/3 - **缺陷:**适用于节点数量较少的联盟链或私有链 - **典型使用场景:**Hyperleder Fabric ## 区块链自身改进 ### 共识算法 - PoW:各节点所计算出的都是一串具有特殊前缀的散列值 - 问题1:没有附加价值,浪费太多资源 - 改进:(特殊前缀散列值)→(具有潜在科学价值的素数) - 保持以下特性: - 被其他节点有效验证 - 不可重用 - 难度可调整 - 问题2:系统吞吐量并不太高(区块大小限制→包含事务有限) - 改进:将共识过程解耦为两个操作 1. 选举产生新区块的领导者 2. 将事务序列化添加到区块链中 - 特性: - 领导者单方面主导一段时期 - 下一个领导者节点不可被预测 - 随机产生的领导者可以被其余节点所验证 ### 可拓展性 **可扩展性的问题:** - 吞吐量问题 - 问题描述: - 比特币目前每秒处理的事务大约是7笔(Visa系统每秒处理上万笔) - 由于块大小的限制,事务被包含到块中需要等待 - 缩短生成区块的间隔 → 区块链分叉的问题 - 成本问题 - 问题描述: - 比特币/以太坊的现有机制:用户创建事务,需要向矿工付费 - 容量问题 - 问题描述: - 节点需要存储自创世区块以来全部的区块副本 - 所有事务全存一个链中 → 容量太大而无法维护 **提高可扩展性的思路:** - 改结构 - Tangle: 基于有向无环图的结构 - ×(链式结构)同步一致 - 每个区块都有前一区块的散列值 - 提交新事务之前,验证上一区块的散列值 - 广播一个区块 - √(Tangle)异步一致 - 每个事务都有{验证次数}权重 - 提交新事务之前,验证两个以前的事务 - 广播 “新事务+两个旧事务” - 不改结构 - 链上解决方案 - 调整区块的大小和生成区块的间隔时间 - 分片技术 - 将一个大型网络划分成一些小的委员会 - 每个委员会通过运行PBFT这样效率更高的共识算法来处理一组互不关联的事务 - 链下解决方案(例如:闪电网络) - 不是每一笔交易事务都有必要放到区块中通过PoW共识得到全网确认 - 而是允许将一部分交易的记录和确认放到链下完成 - 跨链解决方案 - 多条区块链之间的相互合作,来提供更丰富的功能和更强的性能 - 目标:将另一个区块链的功能引入当前的区块链 - 重点:多个区块链系统之间的通信和数据传输 ### 防攻击 - 51%攻击:具有全网一半以上的算力就可以操纵新区块的生成 - 自私攻击:为了获得不适当的奖励而浪费诚实矿工的计算能力 - 攻击者不广播挖掘到的区块而是私下持有,之后自私的攻击者们会在这条私有链上继续进行挖矿,并试图保持一条比公共链更长的私有分支 - 边界网关协议(BGP)劫持攻击:劫持路由延迟网络消息 - 可以使比特币网络分叉 - 或者延迟块传播的速度 - 僵尸网络攻击:具有不同IP地址的机器人,独占受害者的输入输出信道 - 使受害者节点与网络其他节点隔离吗,从而接收不到区块链的最新消息 - 活跃攻击:(针对以太坊网络)能尽可能延迟目标事务的确认时间 针对安全攻击的问题,现有的主要解决方案是提出新的矿池。 ## 典型区块链应用 - 金融和市场领域应用 - 电子加密货币:比特币、以太坊 - 构建点对点金融市场 - 跨域金融资产的清算结算 - 供应链流程追溯管理 - 声誉系统 - 安全和隐私增强 - 帮助构建更可靠的公私钥基础设施 - 匿名存储系统 **区块链应用到物联网、车联网、边缘计算等场景:** - 三种类型的节点 - 轻量级节点 - 终端设备 - 保留一个带有区块链地址和余额的钱包 - 只执行提出交易等任务 - 标准节点 - 保存部分区块链的副本信息 - 主要是收集轻量级节点的交易或相应轻量级节点的查询 - 交换级节点 - 保存了区块链的完整副本记录 - 可以提供区块链的分析服务 ## 边缘计算 > 云服务器应该被转移到更倒进终端用户的地方,即移动网络的边缘节点 - 涵盖技术: - 软件定义网络(SDN) - 面向服务计算(SOC) - 计算机体系结构 - 等 - 核心思想: - 将计算和通信资源从云转移到网络的边缘节点上,从而为边缘用户提供更快的服务于计算响应,减少中间不必要的通信延迟和网络拥塞。 - 边缘计算范式的建立,基于: - 网络虚拟化(network function virtualization, NFV) - 单个边缘设备能向多个终端设备提供计算服务 - 边缘设备×1 => 虚拟机×n - 同时执行不同的任务或操作不同的网络功能 - 信息中心网络(information-centric networking,ICN) - 端到端的服务识别范式 - ~~(以主机为中心)~~ -> (以信息为中心) - 从而实现可感知内容的计算 - 软件定义网络(software defined network,SDN) - 服务抽象 → 管理服务 → 动态的可伸缩的计算 - 边缘计算的好处: - 对移动运营商 - 更加灵活便捷的方式部署服务,根据使用的服务进行收费 - 比如提供存储资源、计算资源或其他IT资源 - 对服务提供商 - 可以提供支持更高带宽和更低延迟的服务,并从这种更好的服务中获取利润 - 对终端用户 - 用户体验得到有效提升 - 与服务者的物理距离更短、无线接入网更加密集 - 更高吞吐量的浏览、更快的视频缓存、更及时的域名系统相关服务等 ## 边缘智能 - 多设备协同的“多设备” - 不仅仅局限于边缘终端设备 - 将充分利用终端设备、边缘服务器、云数据中心 - 多个边缘设备协同计算共建人工智能 - {任务卸载}一个同样的人工智能算法通过多个设备协同完成计算 - {群体智能}相互连接和组织在网络中的松散耦合的多个智能体 - 智能体:单个设备 或 小型设备集群 - 拥有可消耗的知识 - 由自身利益的目标驱动 - 为了实现群体目标与其他智能体交互 - 例如共享知识数据或联合进行决策 - 发展趋势 - 安全与隐私问题 - 网络性能 ## 边缘智能+区块链 ### +区块链的原因 1. 边缘人工智能计算中的**节点本身**及在**相互通信的过程**中都可能遭到网络攻击 2. 参与边缘智能的节点**可能存在恶意行为**或者缺乏足够的**激励**而为系统积极贡献 ### +区块链的研究 - **文献:**[88] - **应用场景:**联邦学习 - **关注问题:**安全问题 - {分散的节点} → {集中的服务器} : 更新参数 - 容易受到**网络攻击** - 存在**隐私泄露**问题 - **区块链作用:**安全可审计的交换模型参数 - 区块链 ← 交换学习模型参数的安全方法 - {节点} → {区块链} : 参数 - {节点} ← {区块链} : 参数 - {区块链}:审计任意时期的子模型 - 《Blockchain analytics and artificial intelli-gence》 - **文献:**[89] - **应用场景:**联邦学习 - **关注问题:**单点故障问题 - {主服务器}:模型初始化,聚合参数 - 主服务器被攻击 → 其他节点无法获知全局模型 - **区块链作用:**安全存储全局模型 - 《FLchain: federated learning via MEC-enabled blockchain network》 - 全局模型状态树 - 全局模型 → Merkle-Patricia树 → 存入区块链 - **文献:**[90] - **应用场景:**联邦学习 - **关注问题:**信任问题 - **区块链作用:**共识验证模型结果+激励 - **文献:**[91] - **应用场景:**联邦学习 - **关注问题:**信任问题 - 节点可能是恶意的 - 节点可能缺乏参与系统的动机 - **区块链作用:**可信加密可审核存储参数+激励 - 《Towards fair and decentralized privacy-preserving deep learning with blockchain》 - DeepChain - 在三个方面提供支持 - 数据保密性 - 计算可审核性 - 激励各方参与协同训练 - 启动事务 → 汇聚子模型参数 → 奖励DeepCoin - **文献:**[92-93] - **应用场景:**联邦学习 - **关注问题:**安全问题 - 中毒攻击 - 信息泄露攻击 - **区块链作用:**安全存储模型更新信息 - 《Biscotti: a ledger for private and secure peer-to-peer machine learning》 - 区块链:存储、聚合信息 - 拒绝负面影响(RONI):删除中毒的更新参数 - 《On-device federated learning via blockchain and its latency analysis》 - 区块链 → 安全的协同训练机制 → 识别并排除拜占庭成员 - **文献:**[94] - **应用场景:**联邦学习 - **关注问题:**安全问题 - **区块链作用:**记录设备操作信息日志,共识识别拜占庭设备 - **文献:**[95] - **应用场景:**联邦学习 - **关注问题:**信任问题 - 缺乏激励 → 懈怠工作 → 上传伪造的参数 - **区块链作用:**分布式信誉管理 - 《Incentive mechanism for reliable federated learning: a joint optimization approach to combining reputation and contract theory》 - 区块链:不可篡改的信誉管理 - 信誉:衡量设备的可靠性、可信度 → 选择FL参与节点 - 边缘服务器 ← 区块链存储节点 + 矿工 - **文献:**[96] - **应用场景:**医疗大数据 - **关注问题:**安全与隐私问题 - **区块链作用:**安全私密的共享医疗记录数据集 - 《Transform blockchain into distributed parallel computing architecture forprecision medicine》 - 体系结构: - 分布式数据管理 ← 智能合约+监控节点 - 分布式数据共享 ← 智能合约+监控节点 - 分布式计算分析 ← 联邦学习+转移学习 - 区块链: - 有助于建立大型核心初始数据集 - 保障所有数据的透明度和完整性 - 监控节点: - **监视**希望访问数据集的所有相关**智能合约事件** - 提供及时响应 - **文献:**[97] - **应用场景:**多机器人系统 - **关注问题:**任务匹配 - **区块链作用:**存储记录分配方案 - 《A decentralised approach to task allocationusing blockchain》 - 动态的基于市场的任务分配方法 - 任务发布者 → 智能体 : 任务 - 联盟链:负责发布者与智能体的通信、协调、信息共享 - 智能体 → 区块链控制器 → 获取任务 → 计算报价 - 决定执行:投标 → 广播给其他智能体 - 放弃竞标:竞标下一个任务 - ==> 所有智能体都同意当前方案 - **文献:**[98] - **应用场景:**多机器人系统 - **关注问题:**信任问题 - **区块链作用:**智能合约进行信誉管理 - 《Trusted registration, negotiation, andservice evaluation in multi-agent systems throughout the blockchain technology》 - 基于Hyperledger Fabric的“多智能体任务协作系统” - 智能体 → 区块链 - 发布自己可以提供的服务 - 选择自己请求的服务 - (利益驱动 → 恶意行为)← 信誉管理 - 另一个区块链账本 ← 评估智能体 - 智能合约 ← 信誉管理 - **文献:**[99] - **应用场景:**无人机集群 - 多架无人机分别从多个视点感知信息 - **关注问题:**分布式决策 - 例如前方如何避障 - **区块链作用:**以转账代表决策倾向 - 《The blockchain: a new framework for robotic swarm systems》 - 一架无人机 → 区块链 : 特殊的事务 - 特殊的事务:包含决策的不同选项对应的**数字地址** - ①该事务得到全网节点的确认之后 - ②其他集群成员可以对自己支持的选项进行**投票** - 数字地址=钱包,投票=转账 - **文献:**[100] - **应用场景:**车联网 - **关注问题:**安全与隐私问题 - (交互数据 → 恶意利用/篡改) ← 区块链 - 区块链 → 匿名数据传输+批量认证 - **区块链作用:**安全隐私可追溯的存储车辆与设施交互数据 - 《Blockchain-enabled security in electric vehicles cloud and edge computing》 - **文献:**[101] - **应用场景:**物联网 - **关注问题:**安全问题 - **区块链作用:**安全存储决策结果 - **文献:**[102] - **应用场景:**物联网 - **关注问题:**激励问题 - **区块链作用:**激励知识管理与交易 - 《Making knowledge tradable in edge-AI enabled IoT: a consor-tium blockchain-based efficient and incentive approach》 - 知识付费共享 - 联盟链 → 市场 → 知识管理和交易 - 加密货币 - 智能合约 - 新的共识机制交易证明(PoT) - **文献:**[103] - **应用场景:**金融 - **关注问题:**安全问题 - **区块链作用:**防篡改存储历史金融信息 - 《Internet of smart things-IOST: using blockchain and clips to makethings autonomous》 - 边缘智能:实时数据监测+动态数据分析 - 区块链: - 加密密钥分发和网络权限管理 - 借款等历史信息 → 信用评估 → 提高安全性 - **文献:**[104] - **应用场景:**智能电网 - 电网边缘的自动化监控和审计 - **关注问题:**安全问题 - **区块链作用:**安全可审计的存储能源交易数据 - 《AI enabled blockchain smart contracts: cyber resilient energy infrastructure and IoT》 - 区块链:无密钥签名的基础设施 → 保护关键数据 - 分布式数字账本+对交易数据的密码学签名 → 交易数据完整性 - 电力生产价值链 → 智能合约 → 自动交易和结算 - **文献:**[105] - **应用场景:**智慧城市 - **关注问题:**激励问题 - 基于物联网的可持续共享经济 - **区块链作用:**激励数据分析信息的共享 - 《Blockchain and IoT-based cognitive edgeframework for sharing economy services in a smart city》 - 边缘节点:生成和处理 大量物联网数据 - 人工智能:处理并提取其中重要的事件信息 → 语义数字分析 → 区块链 - 区块链:提供一系列共享经济服务 ### +区块链的好处 #### 增强 计算框架的健壮性 - 传统云中心架构 - 数据在本地 - 人工智能部分工作转移到设备上 - 大量异构计算资源 - 大量可能掉线/被劫持的节点 - 区块链+联邦学习架构 - 各节点利用本地数据分散训练 - 区块链的共识机制 分散地进行数据交换和子模型更新的验证 - 无需任何集中的数据训练或协调 #### 增强 数据管理、存储、传输的可靠性 - 边缘人工智能计算场景的网络是典型的点对点网络 - 多跳链接、缺少中心、缺乏明确防御机制 → 网络不稳定 - 重放攻击、拒绝服务攻击、窃听、虫洞攻击、伪装攻击 - 对边缘人工智能计算场景来说,信息是非常重要的 - 防止隐私泄露 - 防止虚假信息传播 - 区块链 - 多种加密算法 → 保障隐私 - 共识机制 → 保障单点故障的健壮性+避免数据的恶意篡改 #### 激励 信息共享与交易 - 区块链天然的点对点的网络架构 → 边缘智能场景大量分散孤立节点 - 区块链的加密货币 → 促进各节点信息共享的有效激励手段 - 区块链的智能合约 → 有助于构建信息相互分享交易的市场 - 依托区块链技术建立起的信息共享交换市场是安全可靠的 - 每一笔交易都可以经过共识机制的验证 - 也可以有效防止篡改和双重支付问题 #### 提升 人工智能决策的可信任性 - (人工智能≈黑匣子) → 难以从理论上解释 - 区块链 → 点对点场景的安全准确无篡改的交易记录 - 区块链:记录人工智能的中间结果和决策过程 → 增加其透明度 - 有利于公众接受和信任决策 - 便于相关人员审计 - 区块链:有助于 在不需要第三方审核的情况下,以分布式方法形成统一的意见 - 文献119 - 《Idea of using blockchain technique for choosing the best configurationof weights in neural networks》 - 一个交易是一个特定的需求 - 全网的“矿工”训练合适的模型并提交申请 - 执行此任务的“矿工”会比较结果,并将最好的结果写入块 - 使该交易成为一个完整的任务 ## 未来研究方向 ### 区块链性能改进 **提升面向资源受限计算环境的扩展性** - 比特币区块链目前处理事务大约7笔/秒,一笔事务的确认大约需要10分钟 - 不满足实时性高的需求,例如无人机集群避障 ### 区块链应用 **构建跨域/泛中心网络中的分布式信任** - 方式1:基于身份管理和访问控制 - 如果身份被验证为可靠,则其受允许的行为便值得信任 - 难点:如何进行身份的相互验证 - 方式2:基于信誉反馈的方式 - 相关方给出有关信任的评价,综合得出关于某节点值得信任的程度 - 难点:相关评价是否可靠 - +区块链 - 不可篡改性保证记录数据的**真实性** - 可追溯性和共识机制有助于确认记录数据的**可靠性** - 新难点: - 如何通过模拟实验来验证所提方案的有效性 - 如何设定信任的衡量方式 - 如何模拟部分节点不同程度的“不可信”情况 **群智计算与数据隐私的权衡** - 零知识证明 - 一种常见的用于保护隐私的密码学手段 - 零知识通信协议过于复杂 → 容易受恶意软件的攻击 - 非交互式简洁零知识证明技术 → 证明过程需要大量的内存 → 受限设备上很难使用 标签: 边缘计算, 深度学习 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭