边缘智能备忘录 2020-10-14 笔记 暂无评论 1251 次阅读 [TOC] # 两个月以前的问题 ## 边缘计算+深度学习,用什么架构好。 - 首先要有一个灵活的边缘计算框架,然后才能考虑深度学习的部分。 - 以下两个框架都用到了Kubernetes,Docker也有Kubernetes功能,默认是关的。 ### 华为的KubeEdge 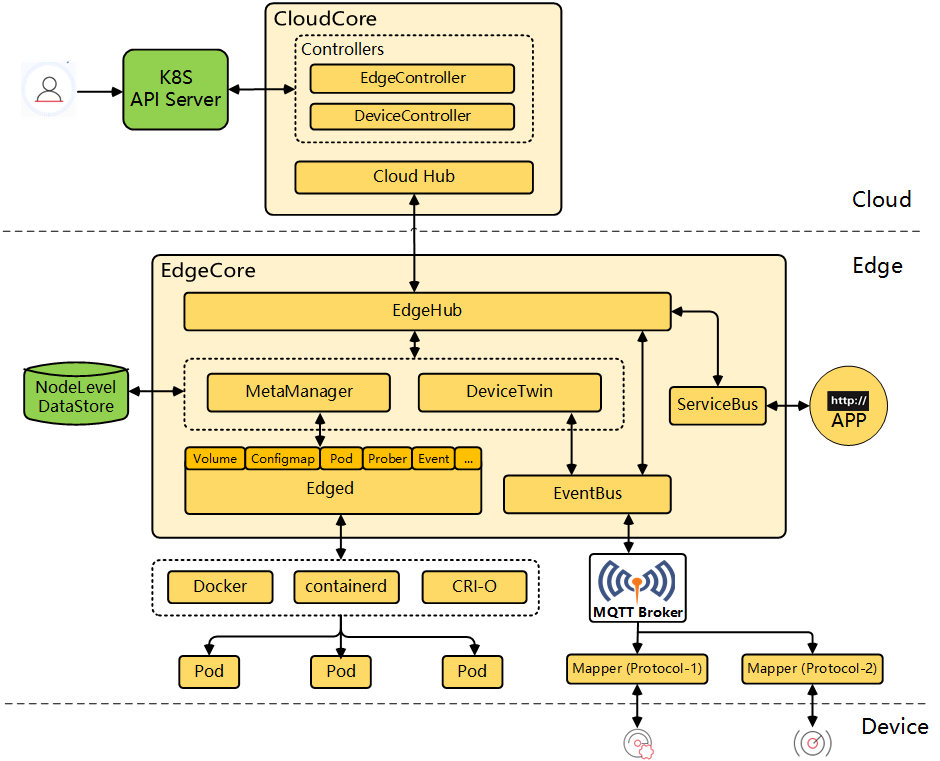 - 这个支持终端设备,是端边云协作 - 要用KubeEdge的话,要了解: - Go语言(感觉边缘计算框架用go语言的比较多) - 用容器(资源受限的设备,容器比虚拟机好) - MQTT通信协议 ### Baetyl(原百度OpenEdge)  - 这个是边云协作,不含终端 ## 感觉边缘场景不适合用区块链,为什么要用区块链。 1. 增强 计算框架的健壮性 2. 增强 数据管理、存储、传输的可靠性 3. 激励 信息共享与交易 4. 提升 人工智能决策的可信任性 ## 有没有什么嵌入式系统,适合用来搞边缘计算+深度学习。 没有。对嵌入式系统(终端设备)来说,最重要的不是深度学习,而是一个规范的通信协议,来把数据发出去。哪怕是接入了区块链,周围所有设备都在为奖励而跑DL,作为数据生产者的终端设备,只需要为跑DL的设备提供数据就好了。如果有余力的话,可以做一些数据预处理的工作。因为干净的数据对DL训练来说,同样重要。 如果不是数据生产者,不知道为什么要用嵌入式系统。 # 新问题 ## 有没有必要弄“区域数据中心” - 可以类比 局域网,城域网,广域网,国际互联网 - 局域网 → 局域数据中心:家庭、办公室 - 可以弄。 - 电脑硬盘划一部分空间,就弄了。 - 虽然是本地,但不能说比传统大数据中心安全,该被黑还是会被黑的。 - 城域网 → 城域数据中心:智慧城市 - 不一定要弄。 - 医院、银行、饭店,数据想打通,方法不止一种 - 烟花模型:每个部门保存自己的数据,别人问就告诉他。 - 热门数据、普通数据、归档数据 要分介质存储 - 加缓存、负载均衡 是必须的 - 区块链:不适合存放数据,但能构建“信任链” - 数据入链很慢 - 数据容量不够 - 广域网 → 广域数据中心:跨城市 - 云计算就是 - 数据越来越多,网络流量逐渐不够用 - 趋势是分摊到边缘,去中心化 - 国际互联网 → 跨国数据中心 - 可以弄,为了全人类的事业。 - 但中心化的网络迟早撑不住。 - 趋势肯定也是去中心化 - 小范围的数据中心+区块链的信任 最好了 ## 要看一个Edge DL平台,主要看哪些点 ### 架构 1. “端-边” / “边-云” / “端-边-云” 2. GPU / FPGA / ASIC 3. 虚拟机 / 容器 4. 模型并行 / 数据并行 ### 必备的 1. 计算虚拟化 ← 虚拟机 / 容器 2. 网络虚拟化 ← VLAN ← SDN控制 3. 网络切片 ← (VLAN → 特定服务) × n ← SDN控制 ### 指标 - 延迟 - 传输延迟 - 执行延迟 - 终端成本 - 设备能耗 - 可靠性 - 网络情况 - 可扩展性 - 差异性 - 隐私 - 准确率 ### 解决挑战 1. 定制模型 - 模型压缩 - 模型修剪 + 恢复 - 参数修剪 与 共享 - 低秩分解 - 转移/压缩卷积滤波器 - 知识蒸馏 - 针对资源预算紧张设备的特殊方法 2. 计算的 - 卸载 - 负载均衡 3. 缓存 4. 与异构物联网设备的通信 # 能用到的东西 ## TDengine 最好的物联网大数据平台 ## uni-app 一个跨平台的前端框架,编写一套代码就可以发布到ios、安卓、H5、微信小程序等10个平台 标签: 备忘录 本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭